
La tendance est indéniablement aux intelligences artificielles de génération automatique de texte : ChatGPT, le nouveau Bing, My AI de Snapchat, le moteur de recherche You et bientôt Google Bard. Pour le moment, toutes fonctionnent grâce à des serveurs, dans le cloud. Mais d’ici à quelques années, à coups d’optimisations et d’augmentation des capacités de nos machines, nous pourrions les faire carburer grâce à nos ordinateurs. C’est déjà le cas, pas avec le modèle de langage le plus connu, GPT-3, mais avec celui de Meta, LLaMA. À cause de la fuite de son code, des développeurs ont réussi à utiliser LLaMa sur leur ordinateur.
Pour aller plus loin
ChatGPT avec GPT-4 : on a reposé nos 8 questions tech
La fuite de LLaMA, le modèle de langage de Meta
C’est ce qui a tout changé selon le développeur open source Simon Willison : la mise en ligne du code source de LLaMA, le modèle de langage publié par Meta il y a quelques semaines. L’aspiration est grande : 65 milliards de paramètres sont pris en compte pour la génération de texte. D’ailleurs, Meta revendique le fait que son modèle surpasse GPT-3 sur la plupart des points.

Là où Meta a souhaité se démarquer de ses concurrents, c’est sur l’ouverture de son modèle. Il a été mis à la disposition des chercheurs, bien qu’il faille accepter certaines conditions strictes, comme le fait de ne l’utiliser qu’à des fins de recherche, sans but commercial bien sûr. Mais comme l’écrit Simon Willison, quelques jours après sa publication, LLaMA a vu son code source publié sur Internet avec tous les fichiers du modèle. C’est désormais trop tard pour Meta : son bébé est dans la nature et on peut l’utiliser en local.
Faire tourner un outil de génération de texte comme ChatGPT sur son ordinateur : c’est possible
Simon Willison a donc exécuté le programme sur son propre MacBook et n’a pas réprimé une certaine émotion : « Alors que mon ordinateur portable commençait à me cracher du texte, j’ai vraiment eu le sentiment que le monde était sur le point de changer, une fois de plus. » Lui qui pensait qu’il faudrait encore des années avant de pouvoir faire fonctionner un modèle similaire à GPT-4, il s’est trompé : « ce futur est déjà là. »

Processeur Intel Core Ultra 9, carte graphique NVIDIA GeForce RTX 5080 et 32 Go de RAM DDR5. Le MSI Vector 16 HX est prêt pour tout. Boostez vos performances avec cette promotion Fnac.
Selon le développeur, « notre priorité devrait être de trouver les façons les plus constructives de l’utiliser », parlant de l’IA. Il ajoute qu’« en supposant que Facebook n’assouplisse pas les conditions de licence, LLaMA sera probablement plus une preuve de concept que les modèles de langage locaux sont utilisables sur du matériel grand public qu’un nouveau modèle de base que les gens utiliseront à l’avenir. » Quoi qu’il en soit, « la course est lancée pour publier le premier modèle linguistique entièrement ouvert qui offre aux utilisateurs des capacités similaires à celles de ChatGPT sur leurs propres appareils. »
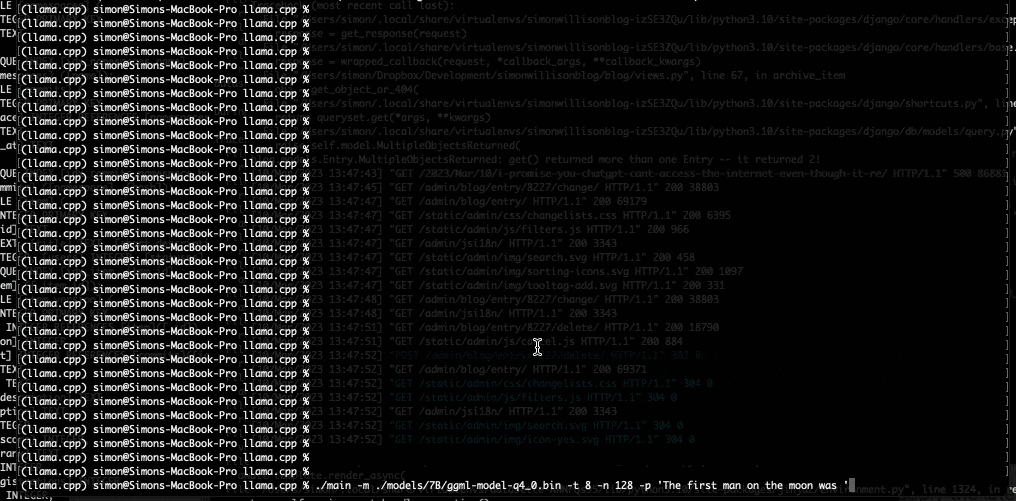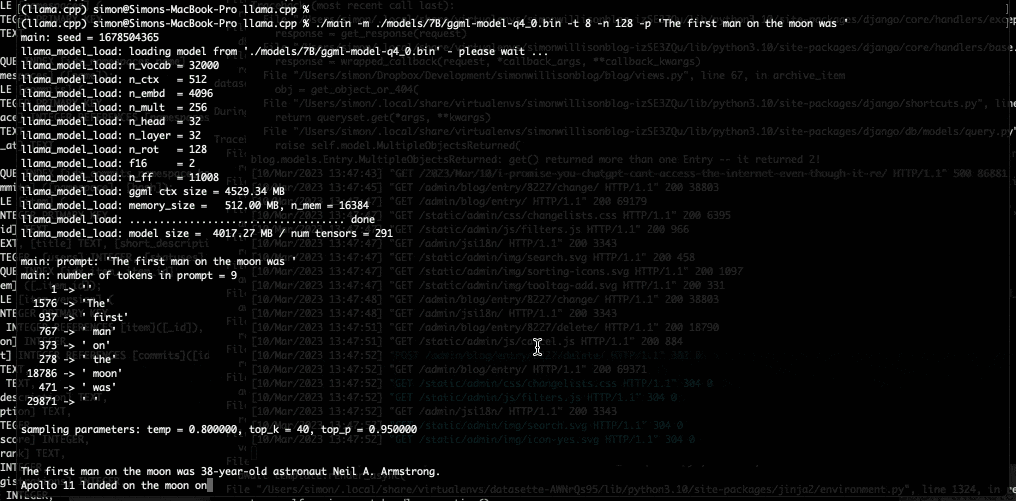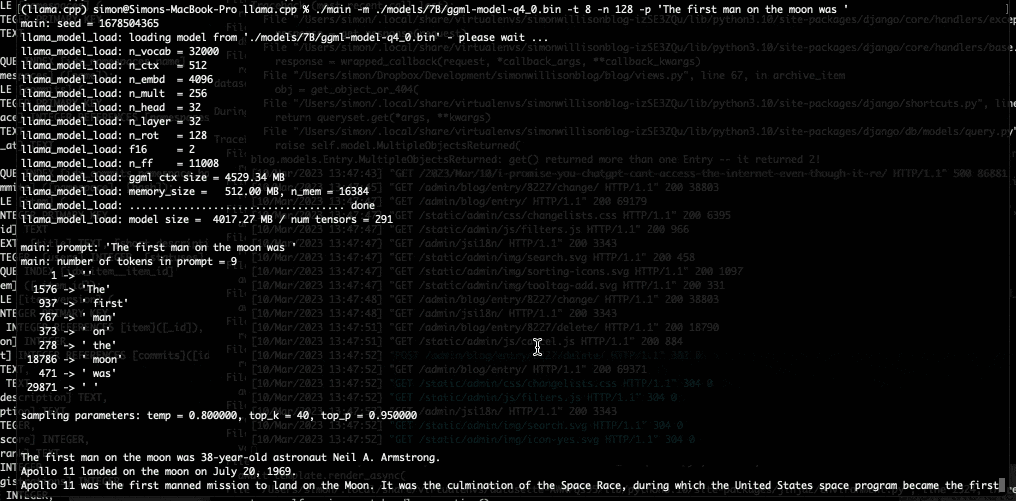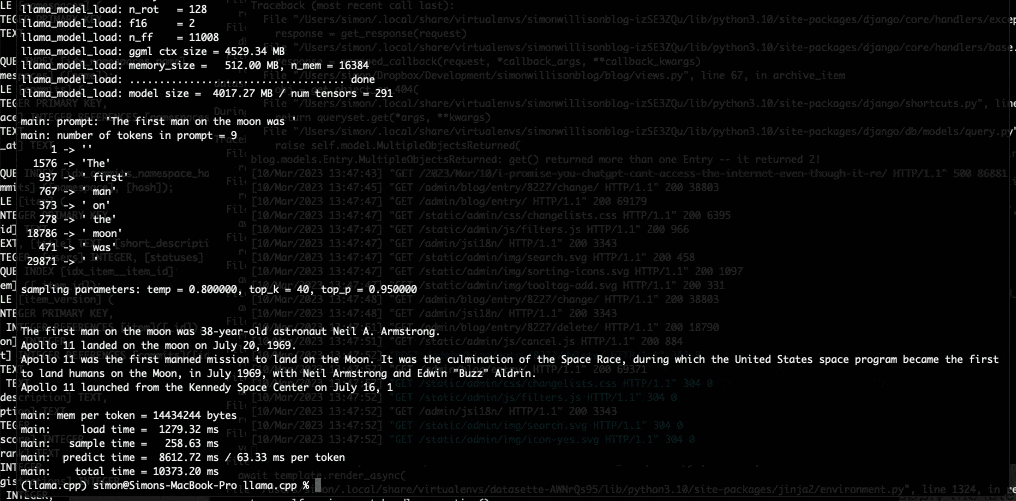
Dans son article de blog, le développeur explique comment il a réussi ce bricolage. Simon Willison parle du projet llama.cpp de Georgi Gerganov, également développeur open source basé à Sofia en Bulgarie. Ce dernier a publié sur Github LLaMA de façon à « faire tourner le modèle en utilisant la quantification 4 bits sur un MacBook. » Simon Willison précise que « la quantification 4 bits est une technique permettant de réduire la taille des modèles afin qu’ils puissent fonctionner sur du matériel moins puissant. Elle permet également de réduire la taille des modèles sur disque : 4 Go pour le modèle 7B et un peu moins de 8 Go pour le modèle 13B. » Les « B » étant ici le nombre de paramètres utilisés par LLaMA, exprimés en milliards.
Les dangers des modèles de langage open source ou qui fonctionnent en local
Toutefois, si c’est une formidable chose pour le monde de l’open source et pour la limitation du contrôle de ces modèles de langage à ces quelques entreprises, cette « libération » a quelques dangers. Simon Willison a même dressé une liste de manière d’utiliser cette technologie pour nuire :
- Génération de spams
- Arnaques à l’amour automatisées
- Trolling et discours de haine
- Fake news et désinformation
- Radicalisation dû à un effet de bulle
Pour aller plus loin
Comment l’IA va transformer le Web, pour le meilleur… et pour le clic
D’ailleurs, ces multiples « ChatGPT » peuvent toujours inventer des choses fausses au même niveau qu’elle peut écrire des phrases factuellement correctes. C’est là aussi que se situe la force des « Gamam » : en donnant accès à leurs modèles de langage via des machines virtuelles, une API ou des outils conversationnels, ils peuvent ajouter des couches de modération. Par des réglages fins et qui doivent constamment s’améliorer, ils peuvent contrôler la manière dont les utilisateurs interagissent avec ces intelligences artificielles. En faisant fonctionner ces dernières en local, on peut perdre ces couches de contrôle.
Seules les grandes entreprises numériques contrôlent les modèles de langage
Finalement, les modèles de langage sont peu nombreux : parmi les plus importants, on compte GPT-4 d’OpenAI, LaMDA de Google ou encore LLaMA de Meta. Si Microsoft ne contrôle pas totalement OpenAI, il a investi environ 10 milliards de dollars dans la société. Annoncé il y a peu, GPT-4 est une nouvelle version majeure de GPT qui prend en compte beaucoup plus de paramètres, pour des performances encore meilleures et une précision accrue. Si l’on dit que l’expression « Gamam » peut paraître réductrice, ce sont en réalité bien ces quelques entreprises privées qui contrôlent les modèles de langage les plus populaires. Les dangers potentiels de ce contrôle sont grands : ils sont en fait des boîtes noires dont on ne sait pas grand-chose.

D’autres initiatives existent, même en France. Chez nous, c’est Hugging Face et son modèle Bloom qui est en tête de proue. Comme l’indique Le Figaro, la société a été fondée par trois Français et est valorisée à 2 milliards de dollars. Un modèle de langage conçu en open source et en collaboration avec le CNRS : il a été « entraîné durant cent dix-sept jours sur le supercalculateur public français Jean Zay, et déjà téléchargé gratuitement par plus de 65 000 professionnels ». L’ambition est claire : Hugging Face rêve d’un Bloom franco-européen qui aille concurrencer ChatGPT. Si ce type d’IA est encore réservé aux grandes entreprises, c’est aussi parce que leur développement demande d’importants financements.
Faire tourner les IA génératives, ça coûte cher
Cette semaine, Microsoft a présenté de nouvelles machines virtuelles dans Azure, sa solution de cloud : elles sont expressément pensées pour l’IA. Mais pour que tout cela fonctionne, Microsoft a fait appel aux GPU Nvidia H100. Une infrastructure chiffrée à des centaines de millions de dollars qui fait de Nvidia finalement le grand gagnant de cette course dans laquelle tous les géants sont lancés. D’ailleurs, cette course pourrait entraîner une nouvelle pénurie de cartes graphiques dans les mois à venir, selon certaines prévisions.
Comme l’écrit Simon Willison dans son article, les modèles de génération automatique de texte sont encore plus gros que les modèles de génération d’images, comme Stable Diffusion, Midjourney ou encore DALL-E 2. Pour lui, « même si vous pouviez obtenir le modèle GPT-3, vous ne seriez pas en mesure de l’exécuter sur du matériel de base – ces modèles nécessitent généralement plusieurs GPU de classe A100, dont chacun se vend au détail à plus de 8 000 dollars. »
Pour aller plus loin
Bing vs ChatGPT : tout comprendre des différences entre les deux IA et leurs limites
En plus d’une grande puissance de calcul, il faut aussi des équipes qualifiées pour créer ces modèles. Pour Simon Willison toujours, si des dizaines de modèles existent, aucun n’arrive à cocher les cases suivantes :
- Facilité d’exécution sur son propre matériel
- Suffisamment puissant pour être utile (équivalents aux performances de GPT-3 ou plus)
- Suffisamment ouvert pour pouvoir être modifié.
Si vous voulez recevoir les meilleures actus Frandroid sur WhatsApp, rejoignez cette discussion.














 au Niger")




Ce contenu est bloqué car vous n'avez pas accepté les cookies et autres traceurs. Ce contenu est fourni par Disqus.
Pour pouvoir le visualiser, vous devez accepter l'usage étant opéré par Disqus avec vos données qui pourront être utilisées pour les finalités suivantes : vous permettre de visualiser et de partager des contenus avec des médias sociaux, favoriser le développement et l'amélioration des produits d'Humanoid et de ses partenaires, vous afficher des publicités personnalisées par rapport à votre profil et activité, vous définir un profil publicitaire personnalisé, mesurer la performance des publicités et du contenu de ce site et mesurer l'audience de ce site (en savoir plus)
En cliquant sur « J’accepte tout », vous consentez aux finalités susmentionnées pour l’ensemble des cookies et autres traceurs déposés par Humanoid et ses partenaires.
Vous gardez la possibilité de retirer votre consentement à tout moment. Pour plus d’informations, nous vous invitons à prendre connaissance de notre Politique cookies.
Gérer mes choix