
Certes, pendant les grèves RATP et SNCF, Google Maps ne s’est pas révélée être la meilleure application de navigation pour arriver en temps et en heure à bon port. Cependant, si l’on omet cette petite erreur de parcours, le célèbre service de cartographie regorge de fonctionnalités devenues quasi indispensables pour bon nombre d’utilisateurs.
Par exemple, Google Maps est capable de vous indiquer la popularité d’un plat dans le menu d’un restaurant ou à quel point un lieu (musée, cinéma, salle de sport…) est fréquenté à telle ou telle heure. Or, pour faire cela, Google a besoin de vos données, mais le géant américain veut aussi rassurer les personnes qui se servent de sa plateforme en garantissant que leurs informations personnelles ne sont pas divulguées. C’est ici qu’intervient un concept important : la confidentialité différentielle.
Nous avons eu l’occasion d’en discuter avec Damien Desfontaines, à la fois ingénieur spécialisé dans la protection de la vie privée chez Google en Suisse et doctorant à l’école polytechnique fédérale de Zurich. L’idée de la confidentialité différentielle consiste à rendre publiques des données sans révéler d’informations sur les individus concernés.
Du bruit dans vos données
Le concept paraît simple ainsi, mais sa mise en application dans des cas concrets est plus complexe qu’il n’y paraît. C’est pourtant ce mécanisme qui vous permet de profiter d’une application Google Maps très complète et précise sans avoir peur qu’un tiers ne puisse deviner quel restaurant vous avez fréquenté ou à quelle heure vous êtes allé boire une bière dans ce bar du centre-ville.
Pour le phraser autrement — et pour reprendre les termes de Damien Desfontaines –, la confidentialité différentielle empêche de déduire les données d’entrée à partir des données de sortie. Sur Google Maps :
- données d’entrée = identité des utilisateurs ayant fréquenté tel lieu à telle heure
- donnée de sortie = graphique indiquant l’affluence dudit lieu à ladite heure
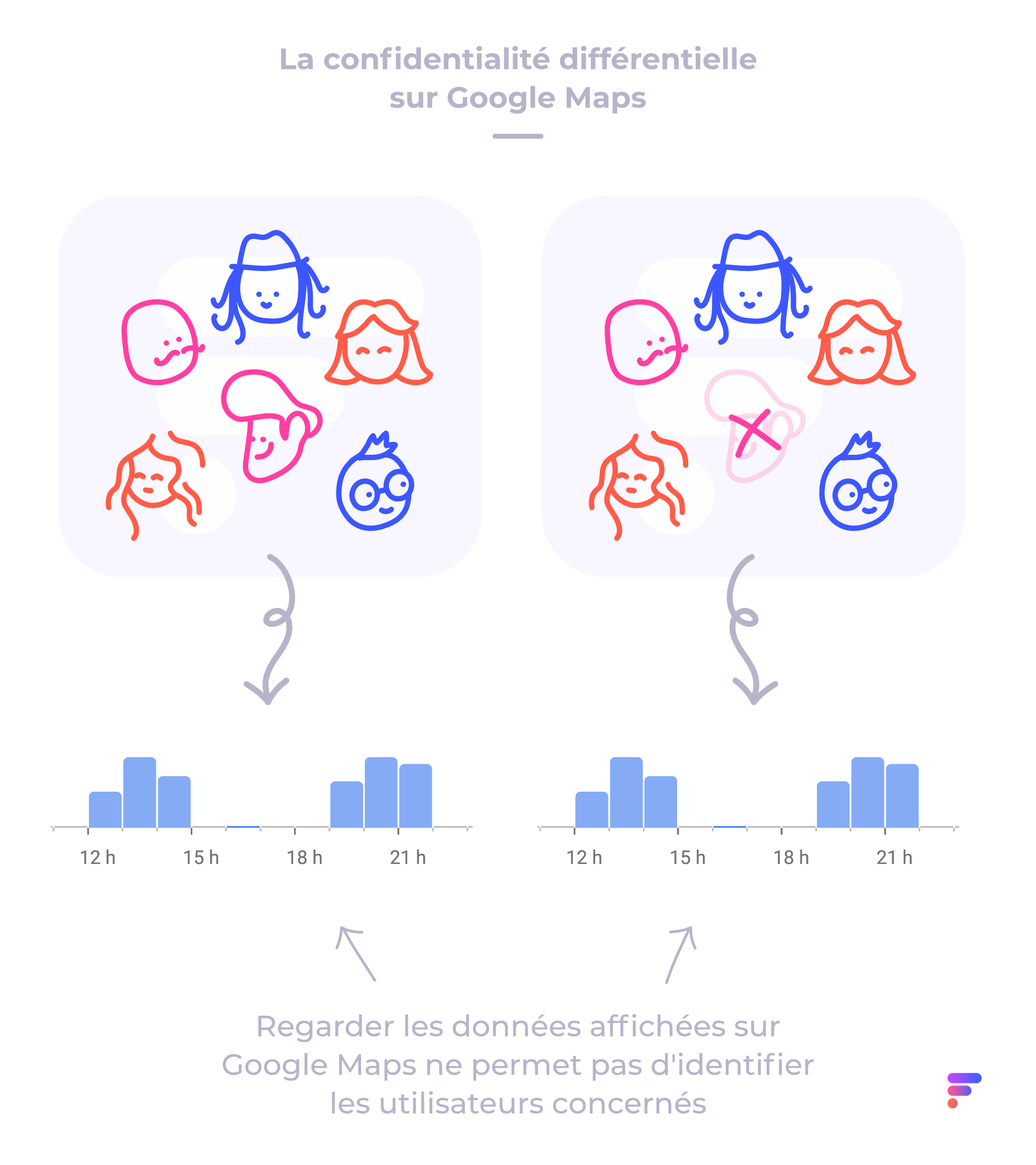
Pour y arriver, la confidentialité différentielle a pour principe d’ajouter du « bruit » aux données publiées sur Google Maps de manière à faire en sorte que si on les compare aux données exploitées par Google, on ne puisse pas y trouver la moindre concordance qui permettrait d’identifier quelqu’un.
Mais ça veut dire quoi « ajouter du bruit » ? Cela consiste à ajouter une petite dose d’aléatoire dans les données de sortie. Imaginons par exemple que Google Maps indique qu’il y a 100 personnes à la salle d’escalade entre 12h et 13h, puis qu’il y a 101 personnes l’heure suivante. Un pirate pourrait, d’une manière ou d’une autre, comparer ces deux groupes de données et isoler la personne supplémentaire afin de découvrir son identité.
Or, grâce au bruit généré par la confidentialité différentielle, cela lui devient impossible. Google Maps va en effet indiquer par exemple qu’il y avait 99 personnes la première heure, puis 103 pendant la seconde plage horaire.
Trouver le bon compromis entre précision et confidentialité
À la fin, même si les données sont moins précises, moins exactes qu’elles pourraient potentiellement l’être, vous avez quand même l’information qui vous intéresse : la salle d’escalade est bondée. Dans le même temps, le hacker ne peut jamais isoler l’identité d’une personne en particulier, tout simplement parce que les données affichées ne changent pas en fonction de cette personne en particulier.
Les données livrées par Google Maps sont donc volontairement un peu floues dans le but de protéger mieux la vie privée. À ce propos, Damien Desfontaines explique que le bruit ajouté dépend forcément de la quantité de données traitées et qu’il faut toujours trouver le bon compromis entre précision et confidentialité.
En d’autres termes, les données sur l’affluence d’un lieu que vous voyez sur Google Maps ne retranscrivent pas le nombre exact de personnes qui y ont été, mais donnent plutôt une tendance assez proche de la réalité pour que vous y trouviez votre compte et assez floue pour que la vie privée de tout le monde soit préservée.
Pourquoi c’est mieux ?
D’aucuns pourraient penser que l’anonymisation des données n’est pas une affaire complexe et ainsi se poser une question tout à fait légitime : pourquoi se donner autant de mal ? Après tout, lorsqu’on s’intéresse à cette problématique, le premier réflexe est sans doute de penser qu’il suffit d’ôter de la base de données tous les éléments identifiant un utilisateur (nom, prénom, âge…). Or, « il est dangereux de croire que c’est suffisant », rétorque Damien Desfontaines.
Il faut en effet comprendre qu’avec une méthode aussi simpliste, il sera toujours relativement facile pour un hacker mal intentionné de déanonymiser une potentielle cible. Netflix nous offre un exemple assez parlant.
En 2006, l’entreprise publie plus de 100 millions de notes attribuées par 500 000 abonnés. Netflix propose alors un prix aux développeurs capables, à partir de ces données, d’améliorer le système de recommandation de DVD mis en place par la firme qui créera l’année suivante la célèbre plateforme de SVoD. Cette base de données avait évidemment été débarrassée des noms et informations personnelles des utilisateurs.
Il est dangereux de croire que c’est suffisant
Cependant, malgré cet effort, deux chercheurs, Arvind Narayanan et Vitaly Shmatikov, ont pu identifier un grand nombre de clients Netflix. Ils ont en effet comparé la base de données de l’entreprise avec celle très fournie du site IMDb (Internet Movie Database).
La manière dont un profil attribue des notes à différents films est assez unique, surtout quand il ne s’agit pas d’un des cent longs-métrages les plus populaires. En retrouvant des correspondances entre les notes attribuées par un profil anonymisé sur Netflix et celles attribuées par un profil non anonymisé sur IMDb, les deux chercheurs ont assez facilement découvert l’identité des personnes.
L’effort de Netflix n’était donc pas suffisant. Damien Desfontaines cite aussi d’autres exemples où cette manière d’opérer a prouvé ses failles. Les conséquences peuvent être très graves comme cette fois où l’on a découvert que les données médicales des patients d’hôpitaux dans l’État de Washington aux États-Unis pouvaient être déduites à partir d’articles parus dans la presse.

Damien Desfontaines explique aussi qu’il est possible de tout simplement agréger. C’est-à-dire créer des groupes de personnes réunies par un point commun. On dévoile ainsi une seule information privée tout en protégeant toutes les autres qui permettraient d’identifier un individu. Par exemple, à la salle d’escalade à 12h, on pourrait dire qu’il y a trente Français, douze Belges, cinq Allemands… sans jamais dévoiler qui compose ces groupes.
Le doctorant explique que c’est un bon début, mais que la solution n’est pas parfaite. En effet, si la base de données indique qu’à 13h, il y a six Allemands, il est possible de déduire que le nouvel arrivant est allemand. Ce dernier devient donc plus identifiable et plus exposé.
Damien Desfontaines explique ainsi que, dans certains cas, si on agrège 100 comptes différents, il suffirait pour un hacker de créer 99 faux comptes afin d’isoler sa victime et savoir exactement quelles sont les données qui lui correspondent.
L’agrégation est donc une solution intéressante, mais qui comporte une faille. Même si celle-ci est difficilement exploitable, il s’agit d’une faiblesse.
Les défis de la confidentialité différentielle
À l’inverse, la confidentialité différentielle appliquée sur Google Maps, entre autres, offre « des garanties formelles » sur la protection de l’identité des personnes, « même avec une base de données auxiliaire », défend Damien Desfontaines. Le chercheur reconnait cela dit que la mise en pratique n’est pas évidente.
Déjà, lorsqu’on applique la confidentialité différentielle dans une collecte de données, beaucoup de choses peuvent mal se passer à cause de mauvaises implémentations et de toutes les subtilités qu’il faut prendre en compte. Il est absolument nécessaire d’utiliser un code robuste.
Aussi, la confidentialité différentielle fait l’objet de plusieurs recherches scientifiques. Grâce à cela, le principe est toujours mieux compris et maîtrisé. Néanmoins, comme le note Damien Desfontaines, beaucoup d’éléments appliqués à la recherche se révèlent tout simplement faux dans la pratique.
« La motivation intrinsèque de la recherche n’est pas forcément de répondre à un cas concret », explique le responsable de Google. Enfin, Damien Desfontaines explique que le nombre de chercheurs dans ce domaine est encore relativement faible, les avancées en la matière ne peuvent donc naturellement pas avoir lieu à vitesse grand V.
Faire adopter la confidentialité différentielle
Damien Desfontaines explique que Google propose en open source un code « testé et robuste » pour faire en sorte que la confidentialité différentielle soit adoptée sur davantage de plateformes. La firme de Mountain View compte également communiquer davantage sur la question pour sensibiliser le public. Un article sur le blog officiel a d’ailleurs déjà été publié.
On l’a vu, le principe est appliqué sur Google Maps, mais Apple en fait de même pour les données récoltées sur ses claviers iOS et macOS, tandis que des modèles de machine learning exploitent également la technique. Fait marquant : le recensement américain en 2020 va aussi faire appel à la confidentialité différentielle pour protéger la vie privée des citoyens.

Notons aussi une autre initiative que Google a voulu mettre en lumière : Private Join & Compute. Il s’agit là d’un protocole qui trouve ses origines il y a 40 ans et qui est utilisé lorsque deux entités ou plus souhaitent calculer des statistiques à partir de données communes sans partager d’informations avec les autres parties.
Pour ne pas confondre les deux principes, retenez que la confidentialité différentielle est utilisée lorsqu’une partie souhaite publier des données sans révéler d’informations sur des personnes et que le principe a commencé à voir le jour il y a 13 ans.
Dans le cadre de Private Join & Compute, Google a, là aussi, mis son code en open source dans l’espoir de faire progresser les choses. Enfin, pour aller plus loin, nous vous invitons à lire l’excellent dossier de nos collègues de Numerama, qui ont également participé à la conversation avec Damien Desfontaines.
Des invités passionnants et des sujets palpitants ! Notre émission UNLOCK est à retrouver un mercredi sur deux en direct, de 17 à 19h sur Twitch. Pensez aussi aux rediffusions sur YouTube !




















Mdr parano parano quand tu nous tient. Moi j'ai un compte non grisé qui se fait ban tous les 3-4 mois pour un nouveau ;)
C'est toi derrière ces grisés... 100%
Bah non jsuis pas grisé, rolala essaye de suivre un peu tes absurditées ^^ Et dans cet article, y'en a qu'un seul de grisé et il critique Google sans parler de Huawei donc faut arrêter la parano. ^^
Tu dois être celui derrière ces commentaires alors... Je n'ai pas parlé dans le vide, tu n'as qu'à lire leurs différents commentaires depuis leur apparition
Lol gardez bien vos oeilleures pour vivre dans votre réalité parallèlle ^^
J'ai en effet deux comptes Google, mais j'ai oublié de vérifier sur lequel j'étais quand j'ai posté mon commentaire ! Erreur de débutant.
Lol pourquoi tu met tes vraies infos aussi
Ça risque pas d'arriver, je n'utilise pas cette daube
J'ai laissé un commentaire positif sur Google maps et quand le commerçant m'a remercié, c'est là que je le suis rendu compte que bah les commentaires son laisse sont nominatifs. Et vu que Google m'incite régulièrement à laisser des commentaires en m'expliquant que je suis célèbre où en le faisant gagner des points chaque fois que je laisse un commentaire, je ne vois pas en quoi la confidentialité différentielle pourrait me protéger. La seule solution que j'ai trouvée est de ne plus poster de commentaire. Problème résolu.
Pourquoi Google allait se gêner pour vos grèves ? N'importe quoi
Ça me fait marrer, ces gens qui se révoltent. Rien ne les empêche de se passer des GAFAM. Il existe pleins de solutions alternatives même si elles restent confidentielles. Car pour que ça marche, il faut une masse critique d'utilisateurs. Donc on a à faire à des organisations totalitaires qui veulent tout simplement nous forcer à ne plus utiliser les GAFAM, pour des motifs flous, juste parce qu'elles l'ont arbitrairement décidé.
Bof ! Article qui fait l'apologie des pratiques d'une entreprise en situation de monopole qui fait de l'exploitation commerciales des données (consenties ou non) de ses utilisateurs sa marque de fabrique. Ce qui fait plaisir est que de plus en plus de personnes en Europe se révoltent contre ces entreprises américaines (les GAFA).
Très belle article bien expliqué
Ce contenu est bloqué car vous n'avez pas accepté les cookies et autres traceurs. Ce contenu est fourni par Disqus.
Pour pouvoir le visualiser, vous devez accepter l'usage étant opéré par Disqus avec vos données qui pourront être utilisées pour les finalités suivantes : vous permettre de visualiser et de partager des contenus avec des médias sociaux, favoriser le développement et l'amélioration des produits d'Humanoid et de ses partenaires, vous afficher des publicités personnalisées par rapport à votre profil et activité, vous définir un profil publicitaire personnalisé, mesurer la performance des publicités et du contenu de ce site et mesurer l'audience de ce site (en savoir plus)
En cliquant sur « J’accepte tout », vous consentez aux finalités susmentionnées pour l’ensemble des cookies et autres traceurs déposés par Humanoid et ses partenaires.
Vous gardez la possibilité de retirer votre consentement à tout moment. Pour plus d’informations, nous vous invitons à prendre connaissance de notre Politique cookies.
Gérer mes choix