
Qu’est-ce qui se cache derrière ChatGPT ? Comment fonctionnent les intelligences artificielles génératives textuelles ? Avec l’émergence des outils d’IA, nombreuses sont les questions autour de leur fonctionnement mystérieux.
En fait, derrière ChatGPT, il y a ce qu’on appelle un « LLM »… Un quoi ?
Qu’est-ce que ça veut dire « LLM » en IA ?
LLM est l’acronyme de l’expression anglaise « Large Language Model ». On pourrait la traduire en français par « grand modèle de langage ». Il s’agit de modèles de langage qui possèdent généralement au moins un milliard de paramètres. En français, on peut aussi les nommer « modèles massifs de langage » et les désigner avec l’acronyme « MML ».
Pour aller plus loin
ChatGPT : son fonctionnement, son potentiel et ses dangers… Le guide ultime pour tout comprendre
Comment fonctionne un large language model, le moteur des intelligences artificielles ?
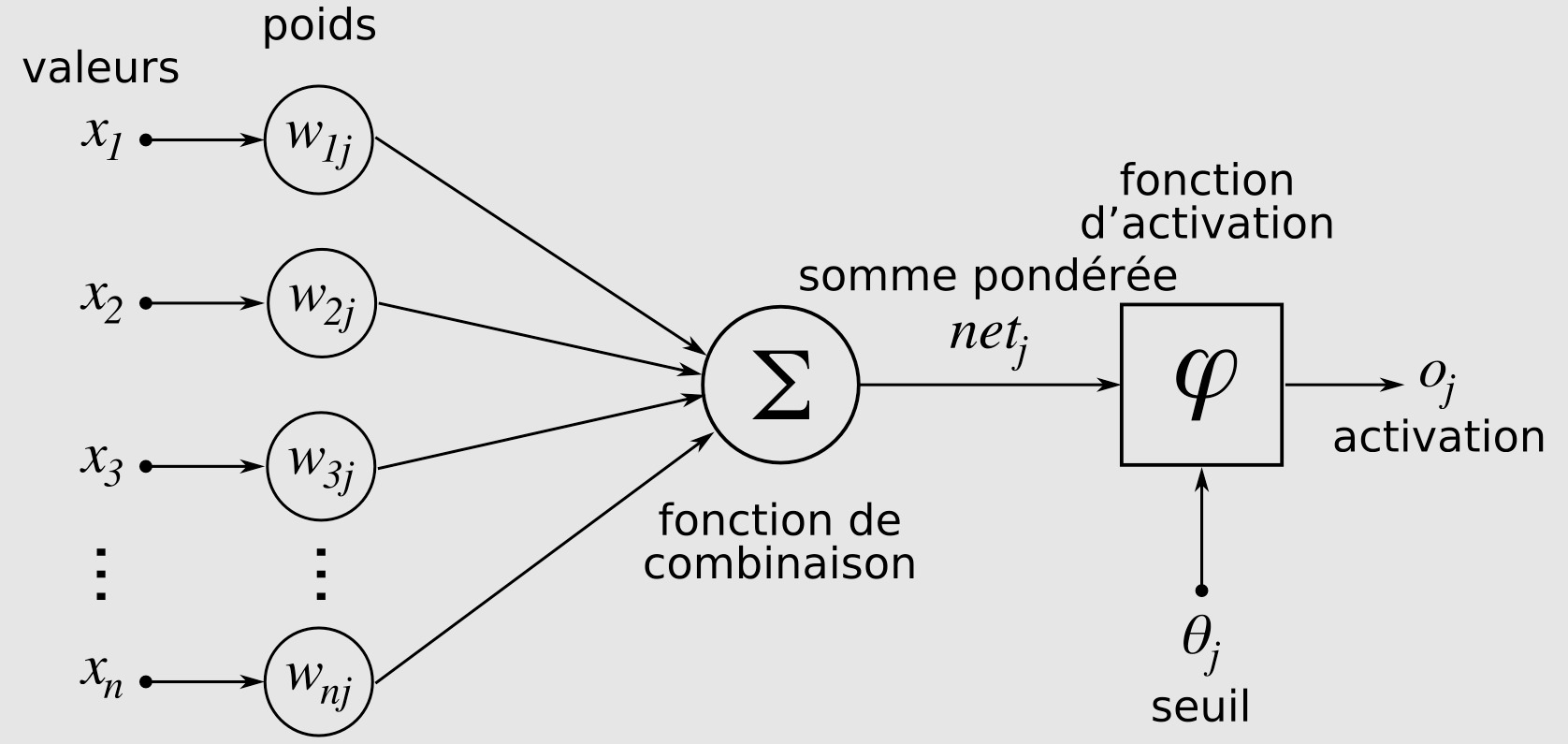
Un LLM, c’est en réalité un réseau de neurones artificiels profonds, soit un logiciel dont la conception est inspirée du fonctionnement des neurones biologiques. Chaque neurone informatique (ou formel) possède des entrées (qui correspondent aux dendrites) ainsi qu’une sortie (correspondant à l’axone). À l’aide de règles précises qu’on lui indique, le neurone formel peut transformer une entrée en une sortie. Ces neurones artificiels sont associés en réseaux selon différents types de connexions (certaines auront plus de poids, ou exécuteront une tâche plus régulièrement).
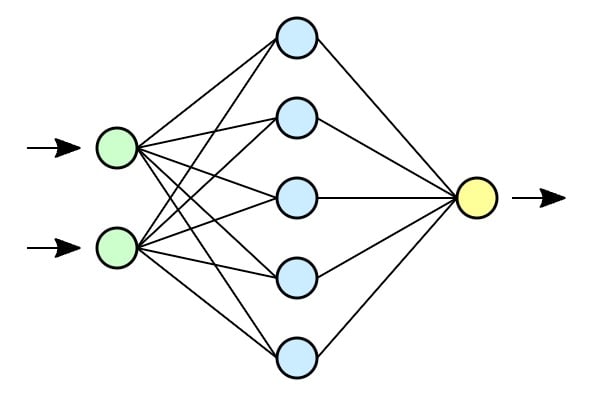
La force de ce système de réseau de neurones, c’est que comme chez l’animal, il peut « apprendre » de lui-même : c’est le machine learning. Mais on peut aller plus loin avec l’apprentissage automatique (appelé deep learning en anglais), qui possède un avantage de taille : il ne nécessite pas qu’un être humain rentre « à la main » tout ce que la machine doit apprendre. De quoi décupler la puissance finale du système.
Pour faire apprendre à un LLM, il faut lui donner du texte, beaucoup de texte. Pour cela, on peut simplement prendre Wikipédia : selon la Wikimedia Foundation, l’encyclopédie en ligne compte plus de 58 millions d’articles en près de 300 langues. Il existe également des ensembles de données textuelles spécialisés dans l’entraînement de LLM, qui sont parfois open source.
La qualité de l’apprentissage dépend aussi de ce qu’on appelle l’étiquetage des données. Dans le domaine de l’intelligence artificielle, l’étiquetage est le fait de donner la réponse à une tâche demandée à partir de données déterminées. Pour du texte, l’étiquetage peut être par exemple de qualifier un texte de « factuel » dans son style, de « familier » dans son vocabulaire, ou bien « d’injurieux » dans ce qu’il dit.
Lorsqu’on partage du texte en entrée à un chatbot, il est transformé en nombres par le LLM, puis analysé, et une sortie est formée en nombres également, avant d’être convertie en texte en sortie. Ces nombres, on les appelle en fait des vecteurs. Comme le précise 01net, ce sont ces nombres qui permettent d’instaurer des scores de proximité entre eux. Plus le nombre possède de chiffres, plus le modèle est complexe, et donc performant. C’est une sorte de mathématisation du texte qui s’effectue et c’est ce qui permet à un algorithme d’imiter le langage humain.
Ce qu’a changé l’architecture Transformer au deep learning
C’est en 2017 qu’un changement technologique va bouleverser le monde de l’intelligence artificielle : la création de l’architecture Transformer. Elle résulte d’une longue combinaison de procédés techniques, avec des travaux datant de nombreuses années.
Un « transformeur », c’est un modèle d’apprentissage profond, principalement taillé pour ce qu’on appelle le traitement automatique des langues. Là où les réseaux neuronaux traditionnels comme les réseaux de neurones récurrents traitent une requête en entrée de manière séquentielle (du début d’une phrase à la fin), le transformeur peut paralléliser cette entrée, afin de considérablement réduire les temps d’entraînement. Réduire les temps d’entraînement, c’est avoir plus d’entraînements pour un coût de fonctionnement de serveurs égal et aller plus loin.
Un bon exemple de l’intérêt de cette architecture est raconté par le philosophe Daniel Andler dans son ouvrage Intelligence artificielle, intelligence humaine : la double énigme. Pour la phrase « j’ai un frère, il est architecte », « frère » et « il » désignent la même personne : la construction de la phrase est simple et les deux termes se suivent. Mais dans la phrase « quand mon frère s’est fâché avec son associé, je lui ai avoué qu’il ne m’avait jamais plu », « mon frère » et « lui » sont éloignés. C’est là que le Transformer utilise un mécanisme d’« auto-attention », qui prend en compte « ces effets à distance du contexte ». C’est ce mécanisme qui permet de prendre un contexte dans le traitement d’une entrée. Un mécanisme qui fonctionne sur deux principes : les « masks » et les « tokens ».
Pour le premier, il y a deux types de masques :
- Les « filtres de causalité » qui vont modifier le poids de certains vecteurs en fonction du contexte donné par la phrase ;
- Les « filtres de padding » qui font en sorte que toutes les phrases aient la même longueur mathématique (autant de nombres en elles), en ajoutant des mots inutiles et non pris en compte dans le traitement.
Ce sont les tokens qui permettent aux réseaux neuronaux de « comprendre » chaque mot en les traitant, pas seulement les uns à la suite des autres. Ils attribuent aussi des liens entre les mots.
Les premiers « vrais » modèles de langage : GPT et BERT
Deux LLM, qu’on peut considérer comme des pionniers, ont été publiés en 2018 à quelques semaines d’écart. Le premier, c’est GPT, pour Generative Pre-Trained Transformer d’OpenAI. Le second, c’est BERT de DeepMind (qui appartient à Google). Grâce à l’architecture Transformer, ils se sont révélés être des révolutions dans les LLM.
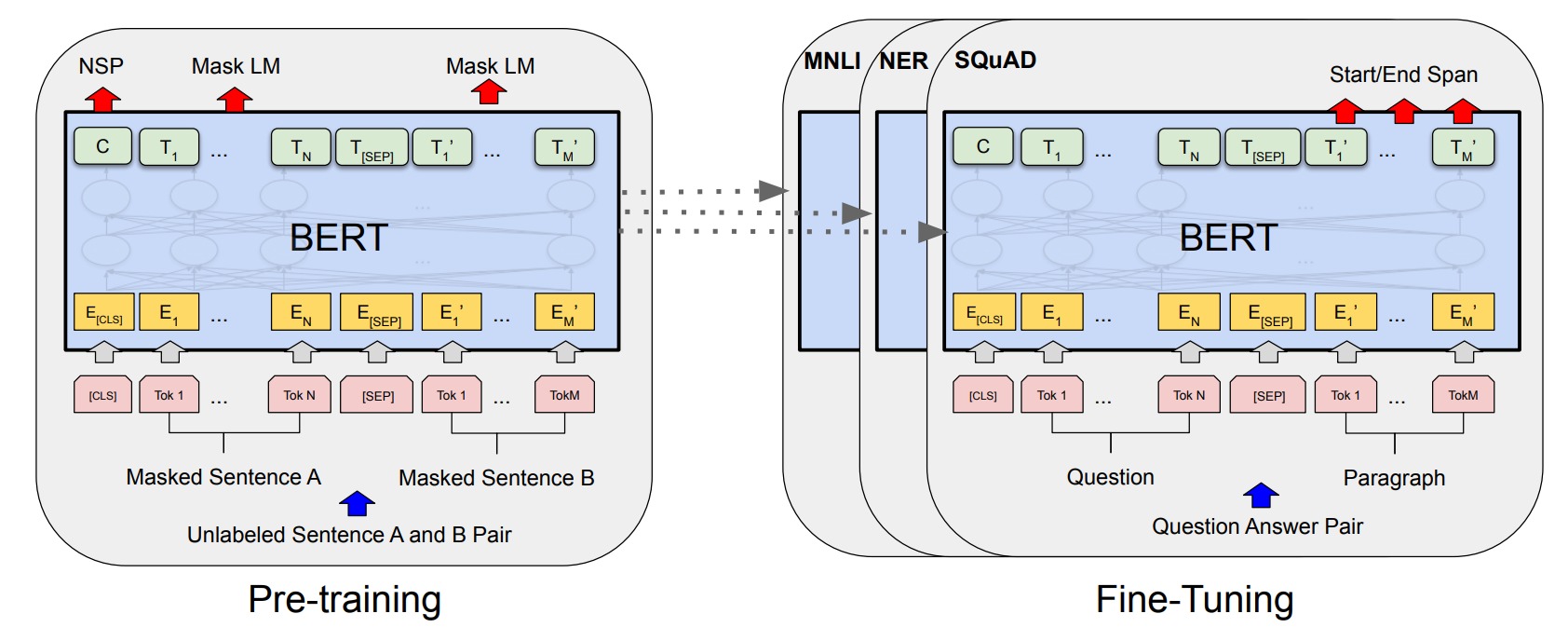
Ils sont très bons en compréhension du langage naturel ainsi qu’en génération de texte. Ils peuvent réaliser des tâches simplement en leur demandant de manière textuelle : « résumer », « traduire », « rédiger ». C’est aussi l’une des premières fois que des modèles de langage ne sont pas pré-entraînés pour une tâche particulière, mais pour tout un ensemble, dont on ne connaît même pas l’étendue.
Pourquoi parle-t-on de « paramètres » pour un modèle de langage ?
Lorsqu’on parle de LLM, on parle beaucoup de « paramètres » : plus il y en a, plus un modèle serait puissant, performant. C’est vrai, mais ce n’est pas une vérité générale. En fait, les réseaux neuronaux contiennent plusieurs nœuds, sur plusieurs couches. Comme l’explique Amazon Web Services, « chaque nœud de chaque couche est connecté à tous les nœuds de la couche suivante ». Chacun a un poids et un écart différent : ce sont ces poids et ces écarts qui sont en fait les paramètres d’un LLM. C’est pour cela qu’on peut « facilement » en avoir des dizaines de milliards. Ce qu’offrent les paramètres, c’est la capacité à davantage capturer de nuances et de complexités dans le langage. Cela permet de prendre en compte des données en entrée plus importantes et des sorties qui le sont aussi. Néanmoins, plus un LLM va loin dans la « compréhension », plus il lui faut de paramètres (de manière exponentielle) et de puissance (de serveurs). Durant la phase d’entraînement, ce sont les poids et les écarts qui sont ajustés de manière itérative.
À quoi servent les large language models ?
La grande force des LLM, c’est précisément qu’ils n’ont pas d’usage précis, puisqu’ils n’ont pas été entraînés sur une capacité en particulier. Leur fonctionnement neuronal fait qu’ils sont entraînés à la prédiction d’une suite probable en fonction d’une entrée donnée (une séquence de mots).

Si vous demandez à ChatGPT de vous raconter une histoire, un conte pour enfants par exemple, il va probablement démarrer par « Il était une fois », puisque c’est très classique. Ensuite, la probabilité de ce qui arrive après est « dans un royaume », ou « une princesse », quelque chose comme cela. En réalité, les LLM ne « comprennent » pas les textes sur lesquels ils ont été entraînés ni ce qu’on leur écrit. Les LLM sont simplement des systèmes statistiques, appliqués à la linguistique. Ils ne déterminent pas que des mots, mais également toute la syntaxe, la conjugaison et la ponctuation de ce qui fait les langues.
Ce qui fait qu’un LLM va être performant dépend de plusieurs facteurs. Tout d’abord, il y a le nombre des paramètres. Plus ils sont nombreux, plus le modèle de langage pourra prendre de facteurs en compte dans sa réponse, ce qui fera qu’elle sera plus précise. D’ailleurs, on découvre certaines capacités en agrandissant le modèle, en augmentant le nombre de paramètres. Comme l’écrit Daniel Andler, « une propriété émerge à partir d’une certaine taille, sans que l’on sache aujourd’hui pourquoi. » La capacité de traduction, la simulation des émotions ou de l’humour en sont quelques exemples.

Cela dépend par ailleurs de la puissance de calcul consacrée au fonctionnement du LLM. Enfin, il y a la qualité des données qui lui ont été fournies en entrée par l’utilisateur. En clair, plus votre demande à ChatGPT est précise, plus le LLM derrière aura de contexte et d’informations pour vous apporter une réponse précise. La qualité des données comprend également la largeur de l’éventail de données qu’il a eu pour s’entraîner, ainsi que la qualité de leur étiquetage. Plus l’étiquetage a été poussé, plus le modèle peut « interpréter » les données d’entraînement et celles qu’on lui fournit lors de la requête.
Quels sont les grands modèles de langage qui existent ?
Depuis l’apparition des premiers grands modèles de langage il y a quelques années, bien d’autres ont été créés. Petit florilège de l’existant en matière d’IA génératives textuelles.
Pour aller plus loin
Les alternatives à ChatGPT : il n’y a pas que le chatbot d’OpenAI qui existe
GPT d’OpenAI
GPT, c’est le plus connu, celui derrière ChatGPT (c’est dans le nom) et sans doute l’un des plus accessibles à ce jour. C’est par lui que l’explosion (médiatique, économique) de l’IA a débuté. La dernière version en date, c’est GPT-4, sorti par OpenAI en mars dernier. Il est encore « plus fiable, créatif et capable de gérer des instructions beaucoup plus nuancées que GPT-3.5 », écrivait l’entreprise. Tout cela principalement parce qu’il est capable de gérer davantage de contexte en entrée (notamment parce qu’il est capable de gérer des images).

Malheureusement, on ne connaît pas sa taille, son architecture ou la manière dont il a été entraîné : OpenAI, malgré un nom qui sous-entend que la société est « ouverte » n’a pour le moment pas donné de détails dessus. Des rumeurs affirment pourtant qu’il serait de 100 000 milliards de paramètres, contre 175 milliards pour GPT-3. Pour le moment, GPT-3.5 peut être utilisé gratuitement via ChatGPT et GPT-4 est réservé aux abonnés à ChatGPT Plus, l’abonnement payant du chatbot. On peut également l’utiliser dans Copilot, le chatbot de Microsoft, mais dans une version moins puissante.
PaLM et Gemini de Google
Google, en tant que géant du numérique, s’intéresse évidemment de près à l’intelligence artificielle. Son LLM le plus puissant s’appelle PaLM, pour Pathways Language Model. Avec ses quelque 540 milliards de paramètres, la dernière version, c’est PaLM 2 (limité à 340 milliards de paramètres). Lui aussi dispose d’un large éventail de tâches : raisonnement mathématique, génération de code, traduction. Pour le moment, seuls certains développeurs y ont accès. Google, par le biais de sa filiale spécialisée DeepMind, a aussi développé Med-PaLM, un modèle de langage dédié aux réponses à des questions médicales. Il a même obtenu l’autorisation d’exercer la médecine aux États-Unis.

Le chatbot de Google, Gemini, ne fonctionne cependant pas avec PaLM, mais avec LaMDA (pour Language Model for Dialogue Applications), un autre modèle de langage de l’entreprise. Il fonctionne avec 137 milliards de paramètres et est performant au point qu’un ingénieur de Google pensait qu’il était doué de sensibilité.
Début décembre 2023, Google a dévoilé Gemini, son nouveau grand modèle de langage. Sa version la plus puissante serait meilleure que GPT-4.
LLaMA de Meta
En 2023, Meta aussi est de la partie avec son propre LLM : LLaMA, pour Large Language Model Meta AI. L’entreprise lui trouve plusieurs usages : c’est un agent conversationnel et un assistant de programmation. La version avec la plus grande taille existante est de 65 milliards de paramètres. En juillet dernier, LLaMA 2 a été annoncé, vendu comme étant un LLM gratuit et open source, le tout en partenariat avec Microsoft. Il devrait être intégré dans Azure AI, Windows, mais aussi dans les smartphones disposant de puces Qualcomm. Par rapport à LLaMA 1, LLaMA 2 a été entraîné sur 40 % de données en plus.
Un système d’IA qui semble fonctionner sur un simple PC : ces derniers mois, les démonstrations se multiplient. Pour le moment, aucun service de Meta ne l’utilise, bien que Meta ait présenté Meta AI, un chatbot qui sera disponible sur WhatsApp, Messenger, Instagram, mais également sur les Meta Ray-Ban et le Meta Quest 3. Une sorte d’assistant à l’image de Copilot, ou de My AI de Snapchat.
Grok de xAI (Elon Musk)
En juillet 2023, Elon Musk lançait xAI, une société spécialisée dans l’intelligence artificielle. Et peu de temps après, c’était au tour de Grok, son propre modèle de langage, avec 33 milliards de paramètres. Il serait meilleur que ses concurrents pour certaines tâches. Contrairement aux autres, il se veut « rebelle » et sans trop de limites, usant d’humour et de sarcasme dans ses réponses. C’est en tout cas ce qu’on constate dans les textes qu’il a générés, qu’on peut lire via des captures d’écran partagées par les membres de xAI.
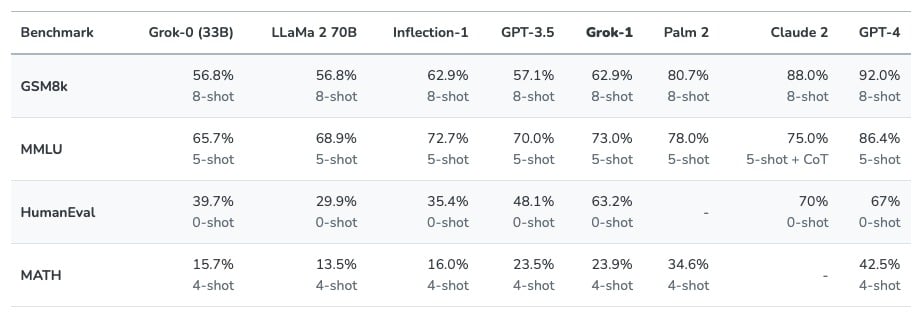
Pour le moment, Grok n’est disponible nulle part, mais devrait l’être dans les mois à venir. Seuls certains utilisateurs américains peuvent le tester pour le moment.
Gauss Language de Samsung
C’est l’un des derniers arrivés : Gauss Language de Samsung. C’est le LLM qui va alimenter Galaxy AI, l’assistant qui sera intégré dans les prochains smartphones Galaxy. Il est nommé d’après le mathématicien Carl Freidrich Gauss, dont la théorie de la distribution normale est utilisée dans l’apprentissage automatique.

Gauss Language permet de réaliser diverses tâches : traduction, résumé de documents, rédactions de mails, etc. Une version est même dédiée à l’assistance à la programmation informatique, Samsung Gauss Code. Néanmoins, Samsung n’a pas dévoilé d’exemples sur les capacités de sa nouvelle IA textuelle.
Titan : le modèle d’Amazon dédié aux professionnels
C’est en avril dernier qu’Amazon a présenté Titan, un modèle de langage maison, principalement capable de comprendre du texte. Il peut tout à fait en générer, mais ne peut pas réellement être utilisé comme tel. Amazon le vend davantage comme une base pour les entreprises souhaitant créer leur propre IA textuelle. Pour l’instant, la disponibilité est restreinte, mais s’étendra dans les prochains mois.
L’Alexa LLM existe aussi depuis peu : c’est le modèle de langage créé par Amazon pour rendre plus « intelligent » son assistant vocal. Cette nouvelle version d’Alexa sera disponible à partir de 2024 a priori.
D’autres modèles devraient émerger dans les mois à venir. Google a notamment levé le voile sur Gemini, et d’autres acteurs pourraient encore émerger avec des solutions alternatives.
Si vous voulez recevoir les meilleures actus Frandroid sur WhatsApp, rejoignez cette discussion.


















Ce contenu est bloqué car vous n'avez pas accepté les cookies et autres traceurs. Ce contenu est fourni par Disqus.
Pour pouvoir le visualiser, vous devez accepter l'usage étant opéré par Disqus avec vos données qui pourront être utilisées pour les finalités suivantes : vous permettre de visualiser et de partager des contenus avec des médias sociaux, favoriser le développement et l'amélioration des produits d'Humanoid et de ses partenaires, vous afficher des publicités personnalisées par rapport à votre profil et activité, vous définir un profil publicitaire personnalisé, mesurer la performance des publicités et du contenu de ce site et mesurer l'audience de ce site (en savoir plus)
En cliquant sur « J’accepte tout », vous consentez aux finalités susmentionnées pour l’ensemble des cookies et autres traceurs déposés par Humanoid et ses partenaires.
Vous gardez la possibilité de retirer votre consentement à tout moment. Pour plus d’informations, nous vous invitons à prendre connaissance de notre Politique cookies.
Gérer mes choix