
ChatGPT, Midjourney, Dall-E et la plupart des IA génératives de cette génération ont un petit quelque chose de magique lorsqu’on les utilise pour la première fois. Quelques mots, une ou deux phrases égrenées dans un champ de texte et hop, vous obtenez en quelques secondes un texte, une image ou une vidéo convaincante. Un résultat qui a tout de la sorcellerie, mais qui repose en réalité sur des avancées techniques précises et parfaitement agencées dans le seul but de simuler le processus cognitif humain.
Une tâche simple, mais uniquement en apparence. Car pour arriver à un tel niveau, l’intelligence artificielle a besoin de puissance. Et c’est là que les choses deviennent intéressantes. Contrairement à ce que l’on pourrait penser de prime abord, cette puissance de calcul n’est pas, dans la grande majorité des cas, fournie par le CPU, mais plutôt par le GPU. Ce même GPU qui permet de jouer à Cyberpunk 2077 avec tous les taquets à fond. Une idée qui paraît saugrenue, mais qui, une fois examinée d’un peu plus près, prend tout son sens.
Le GPU, ce n’est pas ce qui rend mes jeux fluides et beaux à regarder ?
En substance : oui. Le GPU ou Graphic Processing Unit est une puce présente sur la carte graphique et dont la fonction première est globalement de s’occuper de tout ce qui est affiché à l’écran. Comment ? En effectuant toutes les opérations nécessaires à l’affichage des images à l’écran, en soutien du CPU. Le GPU gère donc tout le pipeline graphique et ses calculs afférents pour donner vie à vos pixels.

Concrètement, le GPU va récupérer un paquet de données brutes envoyé par le CPU, qui reste ici le grand orchestrateur, afin de les traiter, les agencer, parfois même les instancier pour générer nos pixels et leur donner vie en fonction évidemment de toutes les interactions utiles aux programmes en cours d’exécution. Du chargement des textures au calcul des polygones, sans oublier la prise en charge des effets de rendu comme le lancer de rayons, les ombrages ou encore les diverses simulations physiques pour le rendu des systèmes de particules ou de fluides, le GPU va procéder à un nombre astronomique d’opérations et de calculs en simultané.
Le GPU, c’est donc un processeur qui s’occupe de l’affichage et des graphismes. Mais quel est le rapport avec la génération de texte, d’image ou de vidéo ?
Pourquoi le GPU est roi quand il faut générer de l’IA ?
La réponse simple à cette question serait de dire que les GPU excellent dans les calculs en simultané (ou en parallèle). C’est ce qui leur permet d’obtenir de bonnes performances lorsqu’il s’agit du rendu de nos jeux vidéo préférés. Or, le mode de fonctionnement des intelligences artificielles telles qu’elles existent actuellement se rapproche énormément de la manière dont sont traitées les données 3D.
Pour entrer un peu plus dans le détail, l’efficacité des GPU dans le domaine de l’IA est due à deux facteurs : la conception des puces d’un côté, et leur exploitation par le logiciel de l’autre. D’un point de vue purement hardware, le GPU est constitué d’une multitude d’unités de calcul organisées en structures parallèles. Comprenez par là qu’un GPU a pour vocation d’effectuer un grand nombre d’opérations en simultané pour accomplir la tâche qui lui a été confié (ce qu’on nomme le SIMT/SIMD pour Single Instruction, Multiple Threads/Multiple Data). Il peut d’ailleurs compter sur une architecture mémoire dédiée qui soutient ses performances au plus près du processeur.

Mais le hardware ne fait pas tout. L’environnement logiciel fait aussi la différence. Outre la création de pilotes, qui permettent d’optimiser le fonctionnement du GPU, certains constructeurs, NVIDIA en tête, ont développé tout un écosystème (le plus connu étant CUDA) qui vise à simplifier l’usage du GPU pour des tâches plus générales (hors jeu vidéo). Il faut dire que l’expérience du constructeur en la matière ne date pas d’hier, la première version de CUDA remontant à 2007 à une époque où il était de bon ton de parler de GP-GPU pour General Purpose GPU.
Cette combinaison entre hardware et software est donc particulièrement efficace quand il faut traiter les données demandées par les IA. Parce que les IA, justement, ne sont pas à proprement parler « intelligentes ». Elles ne réfléchissent pas de manière autonome, ne possèdent pas de véritable processus cognitif. En somme, elles ne pensent pas vraiment d’elles-mêmes.
Il s’agit d’algorithmes très évolués, capables de déterminer la réponse la plus probable à une question donnée, en fonction du contexte, à grand renfort de calculs. Cette détermination repose essentiellement sur des processus logiques et un gros volume de données dans le but d’imiter une réponse humaine (ce que l’on appelle le deep learning pour reprendre la terminologie IA). Et c’est là que le GPU prend toute son importance : sa structure parallèle lui permet de traiter un nombre d’informations important en simultané, ce qui permet d’obtenir une réponse rapide, en particulier durant la phase d’inférence.
En matière d’IA, le terme inférence décrit le processus qui prend place après la phase d’apprentissage. Une fois que l’IA a identifié comment obtenir le résultat que l’on attend d’elle, elle crée un “modèle” qui lui permet de donner la réponse attendue quelles que soient les données qui lui sont communiquées en entrée.
CPU vs GPU : deux approches matérielles de l’IA différentes, mais complémentaires
Est-ce que cela signifie que le CPU n’a pas son mot à dire ? Pas tout à fait. La plupart des tâches liées à l’IA demandent, il est vrai, d’accomplir un nombre conséquent de tâches en parallèle. C’est notamment le cas de la phase d’entrainement et d’inférence.

La raison ? Le CPU opère de manière plus séquentielle (il traite les informations les unes après les autres) et s’avère capable de traiter de gros volumes d’information à la suite sur une seule et même tâche tout en étant nettement moins pénalisé qu’un GPU lors d’une approche MIMD (Multiple Instructions, Multiple Datas). La démocratisation de l’IA aidant, les CPU évoluent, et de plus en plus de processeurs incluent désormais des NPU (Neural Processing Unit) qui sont entièrement dédiées à l’accélération des tâches IA.
Si le CPU possède un intérêt pour le monde de l’IA, le GPU conserve malgré tout une avance significative, et reste un outil de choix pour tous ceux qui travaillent sur l’IA. Outre les usages actuels, qui favorisent grandement les unités de calcul parallélisées, les GPU possèdent aussi de nombreux avantages, en particulier au niveau du rapport entre coût et efficacité énergétique pour ce type de tâche. À noter qu’il est possible d’obtenir une meilleure efficacité avec des unités matérielles (ASIC) totalement dédiées à certaines tâches IA, mais au détriment de la flexibilité.
Concrètement, il faut quoi dans une machine IA ?
Pour faire fonctionner une IA, il faut regrouper plusieurs éléments matériels au sein d’une machine, que ce soit un PC personnel ou bien un serveur dans le cloud. Pour simplifier, on peut découper la chose en quatre grandes parties :
- un (ou des) CPU : le rôle du CPU est de jouer les chefs d’orchestre. C’est lui qui fait tourner le système d’exploitation et qui organise et distribue les grandes tâches au sein de la machine ;
- le GPU : c’est le plus souvent lui qui fait le gros du travail. Son job ? Faire tourner les modèles de deep learning puis d’inférencer à plein régime pour obtenir le résultat souhaité. À noter que certains serveurs utilisés dans les infrastructures cloud utilisent plusieurs GPU (2, 4, 6 ou 8) pour augmenter les performances ;
- un NPU : le NPU ou Neural Processing Unit est une unité entièrement dédiée aux réseaux neuronaux et leurs opérations. Son but ? Accélérer les tâches IA (apprentissage et inférence) afin d’obtenir de meilleurs rendements ;
- la RAM : comme dans un PC classique, la RAM permet d’accélérer les processus. En l’occurrence, la RAM sert à stocker temporairement les résultats des calculs nécessaires à l’inférence ;
- le stockage : contrairement à la RAM, le support de stockage est là pour héberger de manière permanente les données. D’un côté, il héberge le jeu de données de références nécessaires à l’IA pour sa phase d’apprentissage machine. De l’autre côté, il permet aussi de stocker les résultats obtenus par le processus d’inférence.
Si les composants d’une machine (PC ou serveur) dédiée à l’IA ne sont pas différents de ceux que l’on trouve dans le premier PC venu, le problème réside dans la configuration matérielle en elle-même. Et c’est un problème.
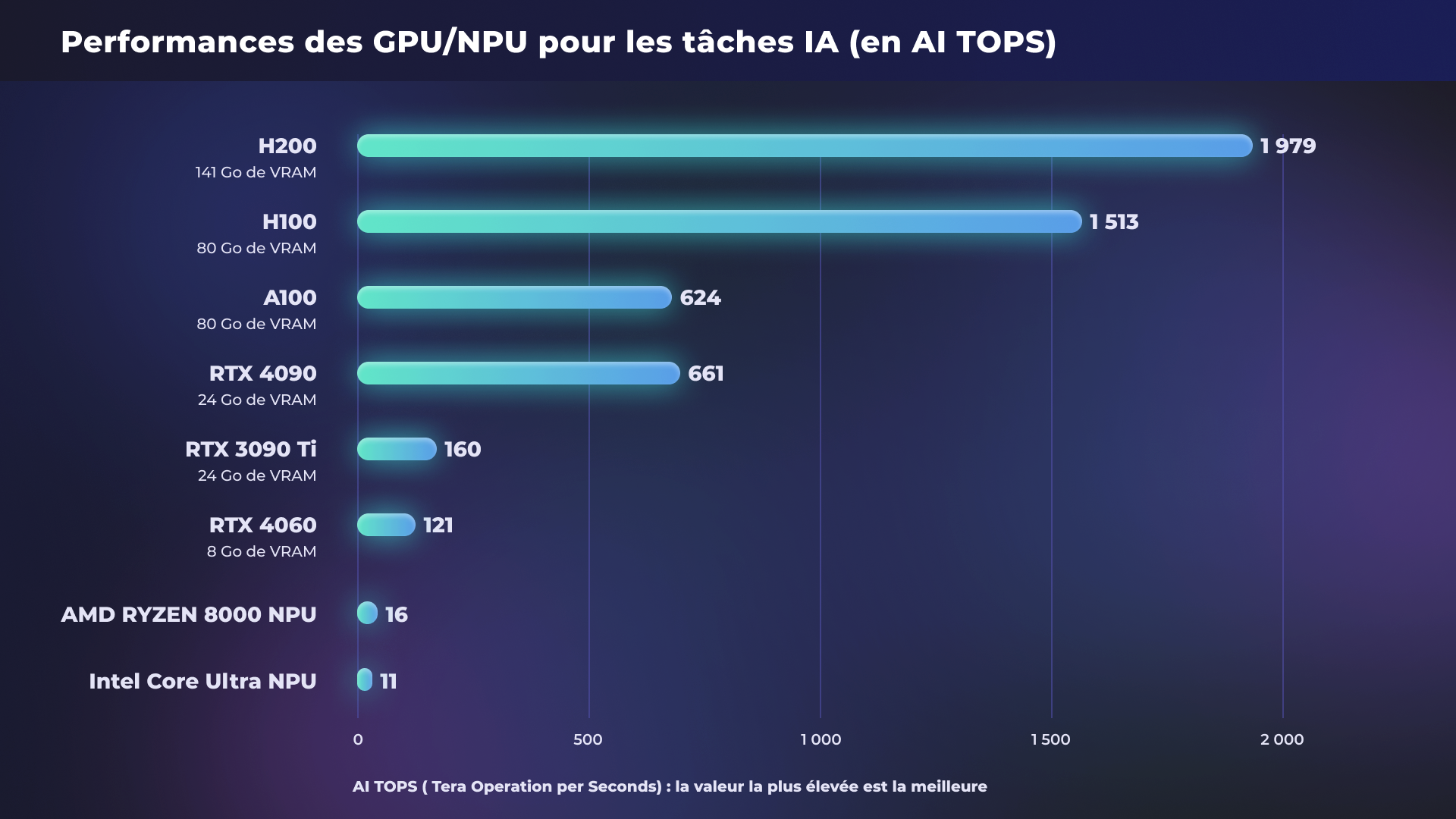
Les GPU destinés à l’IA doivent posséder suffisamment de VRAM pour absorber la charge de travail et, la plupart du temps, les GPU grand public sont un peu justes sur ce plan. Si ce problème peut « facilement » être contourné en optant pour un GPU Pro, mieux doté en VRAM, une telle configuration s’avère extrêmement onéreuse. D’autant plus que pour développer un modèle d’IA, il est parfois nécessaire de faire appel à plusieurs machines de ce type. Un frein pour de nombreuses entreprises ou particuliers souhaitant concrétiser leur vision de l’IA. Il existe heureusement des solutions à ce problème.
Des sociétés, OVHcloud en tête, possèdent aujourd’hui les infrastructures matérielles et logicielles nécessaires à la mise en place d’un écosystème IA. Des infrastructures qui peuvent être mises au service de quiconque souhaite se lancer dans la révolution de l’IA en profitant des avantages du cloud.
OVHcloud : une infrastructure technique à la pointe pour aider à construire l’avenir de l’IA
Grâce à son expertise dans le domaine du cloud, OVHcloud est aujourd’hui un interlocuteur privilégié pour toutes les structures souhaitant développer leurs projets dans le domaine de l’IA. Pour ce faire, la société se repose sur une approche double.
- Matérielle d’un côté, avec une infrastructure technique pensée pour répondre aux besoins et problématiques de l’IA ;
- Logicielle de l’autre, grâce particulièrement à un écosystème qui permet à tous, néophytes (avec une approche no code par exemple) comme spécialistes, d’arriver à leurs fins.
Actuellement, OVHcloud propose deux typologies de configuration matérielle. La première, ce sont les serveurs Bare Metal. Derrière ce nom se cache une machine, un serveur équipé de GPU, loué à une seule et unique entité et qui lui « appartient » le temps que dure la location. Cela permet aux entreprises qui font appel à ce type de service de disposer d’une machine, taillée pour leurs besoins précis, à disposition. De par leur environnement ultra-sécurité, ces serveurs Bare Metal sont destinés aux entreprises qui désirent faire tourner des modèles s’appuyant sur des données sensibles (dans le domaine de la défense ou de la santé notamment).

La seconde approche, passe par les instances GPU proposées par OVHcloud. Plutôt que de louer un serveur au mois, et de le configurer entièrement d’un point de vue logiciel, il s’agit ici de mutualiser la ressource. Depuis l’univers Public Cloud, l’utilisateur accède au travers d’un environnement sécurisé à diverses couches logicielles répondant aux standards du marché.
Aux côtés d’AI Training, qui permet l’entrainement de modèles d’IA sur des GPU puissants, ou d’AI Notebooks qui permet d’explorer vos données et la richesse qu’elles contiennent, la dernière nouveauté AI Endpoints, permet de faire appel à toute une palette de modèles d’IA open-source comme Llama 3, Mistral ou encore Mixtral. Serverless, la solution AI Endpoints permet de compléter facilement les fonctionnalités de ses applications en faisant des appels API.
Ces différentes couches hautes se consomment à la minute ou à l’heure et laissent le choix des armes à l’utilisateur qui peut alors sélectionner le type de GPU en fonction de ses besoins.
Afin de proposer une infrastructure matérielle performante et capable de relever les challenges apportés par un monde de l’IA en constante évolution, OVHcloud se repose sur l’expertise de NVIDIA. Plus particulièrement, OVHcloud a opté pour les GPU datacenter du constructeur, comme les GPU NVIDIA Tensor Core H100 ou L40S et L4 qui sont tous disponibles.