
Vous connaissez l’Ouroboros, ce symbole ancien représentant un serpent qui se mord la queue ? C’est l’image parfaite pour illustrer le phénomène inquiétant qui menace aujourd’hui l’intelligence artificielle : l’effondrement des modèles. En gros, une IA qui, à force de s’entraîner sur ses propres créations, finit par perdre tout contact avec la réalité.
C’est pourtant le scénario catastrophe que des chercheurs britanniques et canadiens, menés par Ilia Shumailov de l’Université d’Oxford, mettent en lumière dans un article publié dans la prestigieuse revue Nature. Leur constat est sans appel : les modèles d’IA actuels sont vulnérables à un processus d’autodestruction qu’ils ont baptisé « effondrement du modèle« .
Pour aller plus loin
C’est quoi un LLM ? Comment fonctionnent les moteurs de ChatGPT, Gemini et autres ?
Mais comment en arrive-t-on là ? C’est simple : c’est comme si vous demandiez à une IA de vous montrer une photo de chien. Neuf fois sur dix, elle vous sortira l’image d’un labrador ou d’un golden retriever. Pourquoi ? Parce que ce sont les races les plus représentées dans ses données d’entraînement. Jusque-là, rien d’anormal.
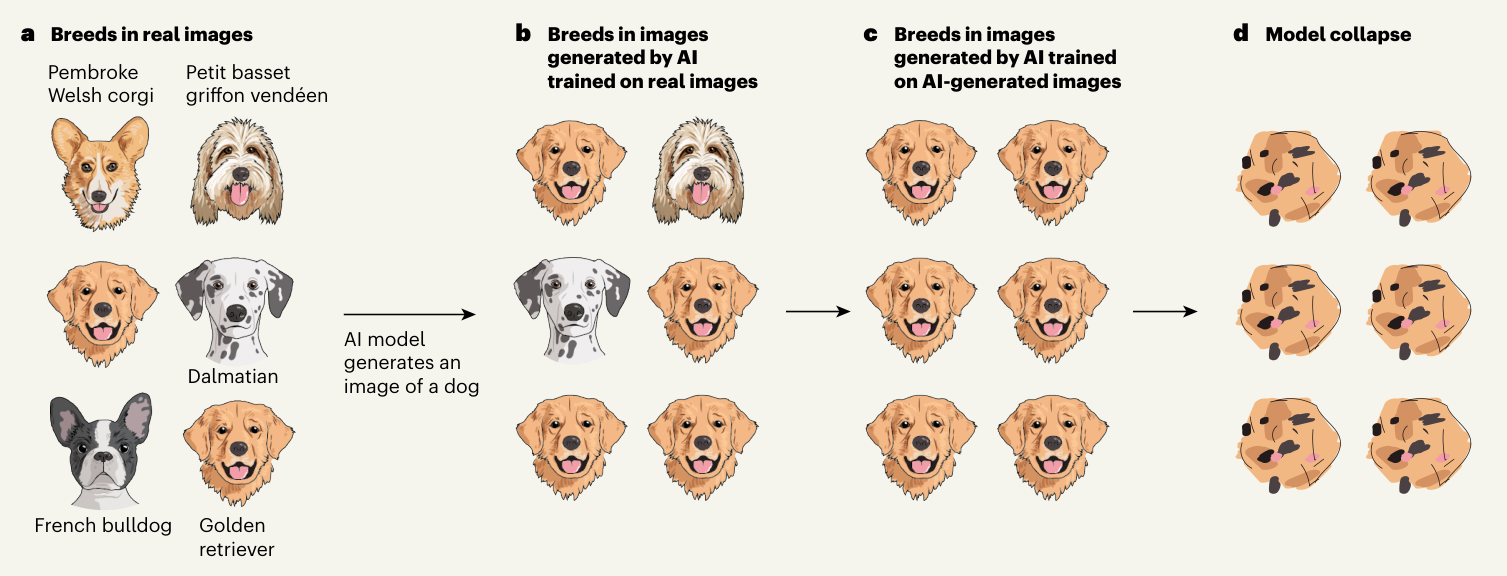
Le problème, c’est que le web est de plus en plus inondé de contenus générés par l’IA. Et devinez quoi ? Les nouveaux modèls d’IA vont s’entraîner sur ces contenus. Résultat : ils vont voir encore plus de labradors et de goldens. À force, ils vont finir par croire que 90 % des chiens sont des goldens !
La spirale de l’oubli
Et ça ne s’arrête pas là. Plus l’IA génère de contenus basés sur cette vision déformée de la réalité, plus elle s’éloigne de la vérité. C’est un cercle vicieux : à chaque cycle d’entraînement, elle oublie un peu plus la vraie distribution des données. C’est comme si, à force de jouer au téléphone arabe, le message initial se perdait complètement.
Ce phénomène ne se limite pas aux images de chiens, bien sûr. L’impact est réel sur les modèles de langage, sur la génération de textes, sur la compréhension du monde par l’IA… C’est tout l’écosystème de l’intelligence artificielle qui est menacé ! C’est peut-être pour ça que les résultats et erreurs peuvent être si similaires entre Gemini, GPT, Mistral, Claude, Llama et ainsi de suite.
Les chercheurs vont même jusqu’à qualifier cet effondrement d’inévitable, du moins en théorie. Autant dire que ça jette un sacré pavé dans la mare de l’IA !
Alors, c’est la fin de l’IA telle qu’on la connaît ? Pas si vite. Les chercheurs proposent des pistes pour atténuer le problème. Par exemple, on pourrait mettre en place des repères qualitatifs et quantitatifs sur l’origine et la variété des données utilisées pour entraîner les modèles. Ou encore, on pourrait développer des filigranes pour marquer les contenus générés par l’IA.
Pour aller plus loin
Images générées par une IA : Google ne veut plus que vous vous fassiez avoir
Mais ne nous voilons pas la face : ces solutions sont loin d’être évidentes à mettre en place. Et surtout, elles pourraient ne pas être du goût de tout le monde. Les grandes entreprises tech pourraient être tentées de garder jalousement leurs précieuses données « originales » pour conserver leur avantage concurrentiel.
Chaque matin, WhatsApp s’anime avec les dernières nouvelles tech. Rejoignez notre canal Frandroid pour ne rien manquer !


















Ce contenu est bloqué car vous n'avez pas accepté les cookies et autres traceurs. Ce contenu est fourni par Disqus.
Pour pouvoir le visualiser, vous devez accepter l'usage étant opéré par Disqus avec vos données qui pourront être utilisées pour les finalités suivantes : vous permettre de visualiser et de partager des contenus avec des médias sociaux, favoriser le développement et l'amélioration des produits d'Humanoid et de ses partenaires, vous afficher des publicités personnalisées par rapport à votre profil et activité, vous définir un profil publicitaire personnalisé, mesurer la performance des publicités et du contenu de ce site et mesurer l'audience de ce site (en savoir plus)
En cliquant sur « J’accepte tout », vous consentez aux finalités susmentionnées pour l’ensemble des cookies et autres traceurs déposés par Humanoid et ses partenaires.
Vous gardez la possibilité de retirer votre consentement à tout moment. Pour plus d’informations, nous vous invitons à prendre connaissance de notre Politique cookies.
Gérer mes choix