Savez qu’il est possible d’avoir votre propre ChatGPT, qui tourne directement sur votre ordinateur, sans dépendre d’un service en ligne ? Les grands modèles de langage, ou LLM (Large Language Models), ne sont plus réservés aux géants du cloud. Aujourd’hui, avec un PC ou Mac correct et quelques astuces, vous pouvez les installer chez vous.
Pourquoi ? Pour garder vos données privées, éviter les abonnements coûteux ou simplement bidouiller une IA à votre sauce. Dans ce guide, on vous explique tout, pas à pas.
Qu’est-ce qu’un LLM ? C’est comme ChatGPT ?
Un LLM, ou Large Language Model (grand modèle de langage en français), c’est une IA entraînée sur des montagnes de textes pour comprendre et générer du langage humain. Concrètement, ça veut dire qu’il peut discuter, répondre à des questions, écrire des trucs ou même coder, un peu comme un super assistant virtuel. Le principe, c’est qu’on lui donne une instruction (un prompt), et il utilise ses milliards de paramètres – des sortes de connexions apprises – pour pondre une réponse cohérente. ChatGPT est un exemple célèbre de LLM, créé par OpenAI, mais il y en a plein d’autres, comme LLaMA, Mistral ou DeepSeek, souvent gratuits et open-source.
Pour aller plus loin
C’est quoi un LLM ? Comment fonctionnent les moteurs de ChatGPT, Gemini et autres ?
Alors, est-ce que c’est exactement comme ChatGPT ? Pas tout à fait. ChatGPT est une version ultra-polie et optimisée d’un LLM, avec des guardrails (des limites) pour rester safe et une interface toute prête dans le cloud. Les LLM qu’on peut installer en local, eux, sont souvent plus bruts : ils dépendent de comment vous les configurez et de votre matos (PC ou Mac). Ils peuvent être aussi puissants, voire personnalisables à fond – vous pouvez les entraîner sur vos propres textes –, mais ils n’ont pas toujours le même vernis ou la même facilité d’accès que ChatGPT. Vous pouvez aussi avoir une interface aussi intuitive que ChatGPT, cela dépend de vos besoins.
Pourquoi installer un LLM chez soi ?
Commençons par le plus gros avantage : la confidentialité. Quand vous utilisez une IA en ligne, vos conversations partent souvent sur des serveurs lointains. Plusieurs pannes chez ChatGPT, Grok ou Gemini ont eu lieu, ces services sont loin d’être 100 % disponibles, et surtout 100 % safe.

Une panne en 2023 chez OpenAI a montré que des historiques d’utilisateurs pouvaient fuiter par erreur – pas très rassurant si vous parlez des données sensibles. Avec un LLM local, tout reste chez vous. Rien ne sort de votre ordi, point final. C’est un argument de poids pour les entreprises ou les paranoïaques de la vie privée.
Ensuite, il y a l’autonomie. Pas besoin d’Internet pour faire tourner votre IA maison. Que vous soyez en pleine campagne ou dans un avion, elle répondra présente. Et côté vitesse, si votre machine est bien équipée, vous évitez les allers-retours réseau qui ralentissent parfois les services cloud. Comme vous allez le voir, même sur un MacBook M1 bien optimisé, un LLM local dépasse un PC classique en réactivité. Ajoutez à ça l’absence de pannes serveur ou de quotas imposés par un fournisseur, et vous êtes libre comme l’air.
Et les coûts, dans tout ça ? À première vue, il faut un peu investir dans du matériel (on en reparle plus loin), mais sur le long terme, c’est souvent plus rentable que de payer une API cloud au mot généré. Pas de facture surprise ni de hausse de tarif imprévue. Une fois votre PC ou GPU prêt, votre IA ne vous coûte que quelques watts d’électricité.
Enfin, le top du top : vous pouvez personnaliser votre modèle. Changer ses paramètres, l’entraîner sur vos propres textes, voire le brancher à vos applications personnelles – avec un LLM local, vous êtes aux commandes.
Mais attention, ce n’est pas magique. Il faut une machine qui tient la route, et l’installation peut intimider les débutants. Les modèles les plus énormes, ceux avec des centaines de milliards de paramètres, restent hors de portée des PC classiques – là, on parle de supercalculateurs. Cela dit, pour des usages courants (chat, rédaction, code), les modèles open-source plus légers font largement l’affaire.
Quels modèles choisir ?
Côté modèles, il y a du choix. Prenons DeepSeek R1, par exemple. Sorti début 2025, ce modèle open-source a fait un carton avec ses versions 7 milliards (7B) et 67 milliards (67B) de paramètres. Il est super fort en raisonnement et génération de code, et sa version 7B tourne nickel sur un PC correct. Autre star : LLaMA 2, créé par Meta. Disponible en 7B, 13B et 70B, il est hyper populaire grâce à sa flexibilité et sa licence gratuite – même pour un usage pro. Le 7B est parfait pour débuter, le 70B demande du lourd niveau matériel.
Il y a aussi Mistral 7B, français. Avec ses 7,3 milliards de paramètres, il bat des modèles deux fois plus gros sur certains tests, tout en restant léger. Idéal si vous avez une carte graphique avec 8 Go de mémoire vidéo (VRAM).
Mistral Small, c’est un des derniers LLM de Mistral AI, la fameuse startup française. Ce modèle, sorti début 2025 dans sa version « Small 3.1 », est conçu pour être léger et efficace, avec 24 milliards de paramètres (24B). L’idée, c’est qu’il soit assez costaud pour rivaliser avec des modèles comme GPT-4o Mini. Concrètement, il peut fonctionner sur un PC ou un Mac sans vous ruiner en hardware, à condition d’avoir un peu de mémoire vive disponible.
Google a aussi son LLM open-source, il se nomme Gemma, une famille de modèles optimisés pour une exécution locale. Gemma 2B et Gemma 7B sont conçus pour fonctionner sur des machines modestes, y compris des Mac M1/M2/M3/M4 et des PC avec GPU RTX.
La liste des LLM open-source s’allonge chaque mois. Mentionnons, au passage, les initiatives comme GPT4All qui regroupent des dizaines de modèles prêts à l’emploi via une interface unifiée. GPT4All supporte plus de 1000 modèles open-source populaires, dont DeepSeek R1, LLaMA, Mistral, Vicuna, Nous-Hermes et bien d’autres.
En somme, vous avez l’embarras du choix – du petit modèle ultra-léger à exécuter sur CPU jusqu’au grand modèle quasi équivalent à ChatGPT si vous avez la machine adéquate. Le tout est de sélectionner celui qui correspond à vos besoins (langue, type de tâche, performances) et à votre matériel.
Comment s’équiper ?
Niveau matériel, pas besoin d’un supercalculateur, même si ces derniers deviennent de plus en plus personnels, avec ce que Nvidia et AMD lancent cette année… et même un Mac Studio.
Pour aller plus loin
Voici les deux premières machines de Nvidia pour faire de l’IA à la maison : des PC qui sont des supercalculateurs personnels
Un PC avec un processeur récent (genre Intel i7 ou AMD Ryzen 7), au moins 16 Go de RAM et une carte graphique NVIDIA (8 Go de VRAM minimum) fait le job. Si vous avez un GPU RTX 3060 ou mieux, c’est le bonheur – grâce à CUDA, ça accélère tout.
Notez qu’un GPU n’est pas obligatoire, mais fortement recommandé pour bénéficier de performances interactives. Pour les LLM, la mémoire vidéo (VRAM) est primordiale : il faut qu’elle puisse contenir au moins une partie des paramètres du modèle. La taille de la fenêtre de contexte (mémoire de la conversation) dépend elle aussi de la VRAM disponible… c’est pour ça que 8 Go de VRAM minimum est le minimum. En pratique : un modèle Llama 7B en 4 bits consomme ~4 Go VRAM, un 13B ~8 Go, un 30B ~16 Go, un 70B ~32 Go. D’ailleurs, même Nvidia pour son outil Chat With RTX exige une RTX 30/40 avec au moins 8 Go VRAM et 16 Go de RAM système.
Pour aller plus loin
Quelle carte graphique choisir ? Les meilleurs GPU de chez Nvidia et AMD en 2025
Sur Mac, les puces M1/M2 avec 16 Go de RAM marchent bien aussi, même sans GPU dédié, grâce à des optimisations comme Metal. Evidemment, plus on a une puce ARM récente et puissante et plus on a de mémoire vive unifiée… mieux c’est.
Pour aller plus loin
MacBook Air, MacBook Pro, Mac Mini… quels sont les meilleurs MacBook et Mac de bureau ?

Découvrez les offres de pCloud : 2, 5 ou 10 To de stockage, situés dans des serveurs européen et sans abonnement, pour 5 personnes. Le gestionnaire de mots de passe est offert !
Stockage ? Prévoyez 10 à 40 Go sur un SSD pour les fichiers du modèle. Avec ça, vous pouvez déjà faire tourner un Mistral 7B ou un LLaMA 2 13B sans galérer. Un SSD est fortement conseillé pour charger plus rapidement les modèles en mémoire… Si vous comptez essayer plusieurs modèles, quelques dizaines de Go de libre sont nécessaires.
Installation d’un LLM sur notre machine
Comme on l’expliquait plus haut, tout dépend de vos besoins, de vos objectifs et de votre niveau technique.
| Niveau | Objectif | Exemples d’outils |
| 🟢 Débutant | Interface simple, prêt à l’emploi | LM Studio, GPT4All, Chat With RTX |
| 🔵 Intermédiaire | Ligne de commande, contrôle plus précis | Ollama, Llama.cpp, LocalAI |
| 🔴 Avancé | Personnalisation, fine-tuning | Hugging Face Transformers, Text-Generation-WebUI |
J’imagine que vous êtes excités désormais, passons donc à la pratique.
Débutant : interface visuelle
L’idée ici est de télécharger un modèle et l’utiliser comme un chatbot, sans passer par des lignes de commande.
LM Studio
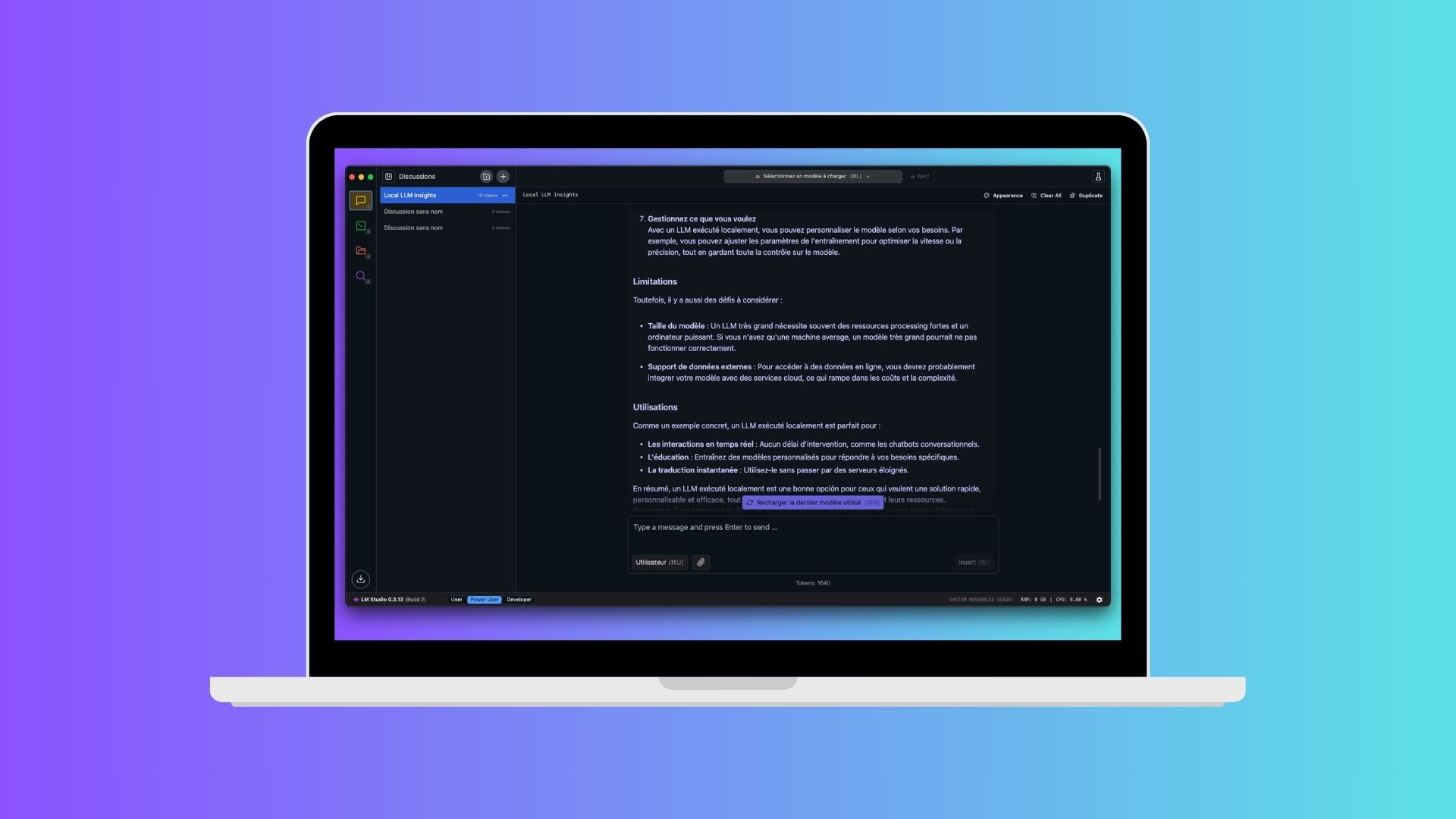
Si vous cherchez une solution prête à l’emploi, sans ligne de commande, avec une interface agréable qui ressemble à ChatGPT, LM Studio est probablement le meilleur choix. Cette application permet de télécharger un modèle, de le lancer et de discuter avec lui en quelques clics.
Sur Windows, macOS et Linux, l’installation est rapide. Il suffit de te rendre sur le site officiel, lmstudio.ai, de télécharger l’installateur correspondant à ton système et de l’exécuter.

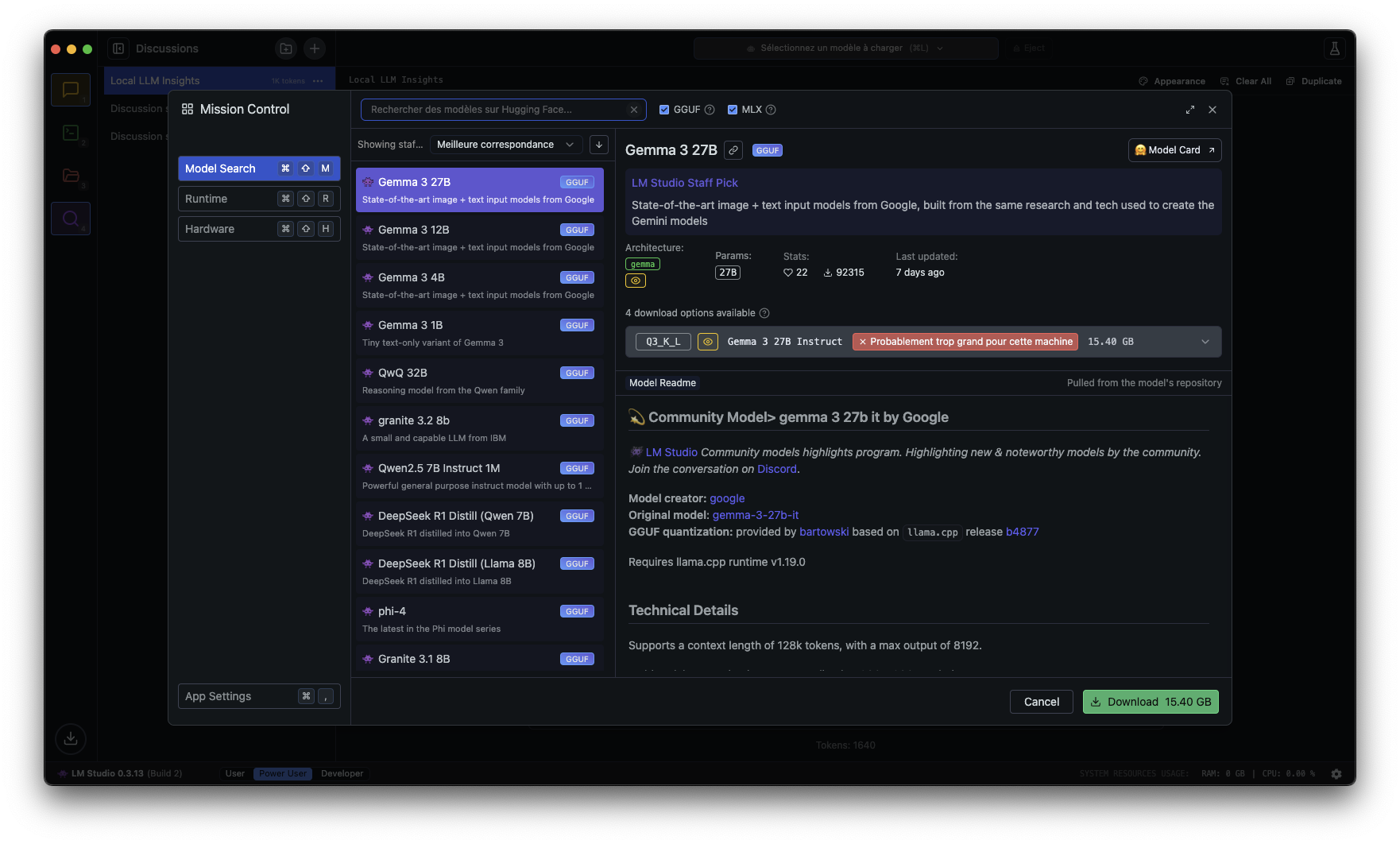
Sur Mac, glisse simplement l’application dans le dossier Applications. Sur Windows, lance l’exécutable et suis les étapes classiques d’installation. Une fois LM Studio ouvert, l’interface te propose d’aller chercher un modèle de langage. Une section dédiée t’affiche les modèles disponibles, avec des descriptions et des recommandations. Pour un bon équilibre entre performances et qualité des réponses, Mistral 7B est un excellent point de départ. Il ne pèse que quelques Go et tourne bien sur la plupart des machines récentes.
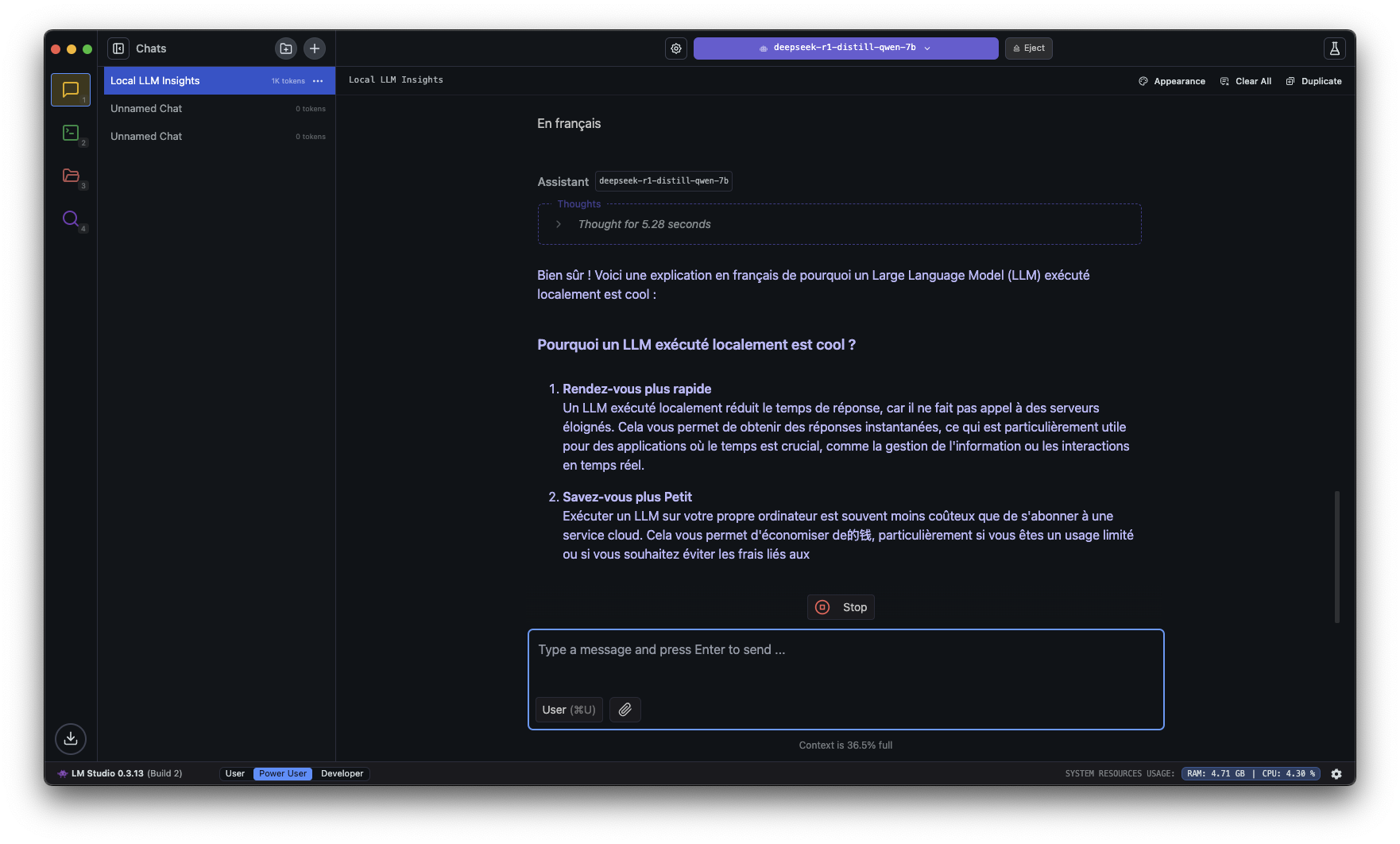
Une fois ton modèle téléchargé, direction l’onglet « Chat ». Vous pouvez taper n’importe quelle question et l’IA vous répond immédiatement, en local, sans passer par un serveur distant. Si vous voulez pousser un peu plus loin, LM Studio permet d’ajuster des paramètres comme la longueur de réponse, la créativité du modèle ou encore la gestion de la mémoire conversationnelle.
GPT4All
Si vous voulez alternative, GPT4All propose une approche similaire. Son interface est un peu plus rudimentaire mais reste simple à utiliser. Là aussi, vous pouvez télécharger des modèles open-source comme Llama 2 ou DeepSeek, et les utiliser en local avec une interface de chat intuitive.
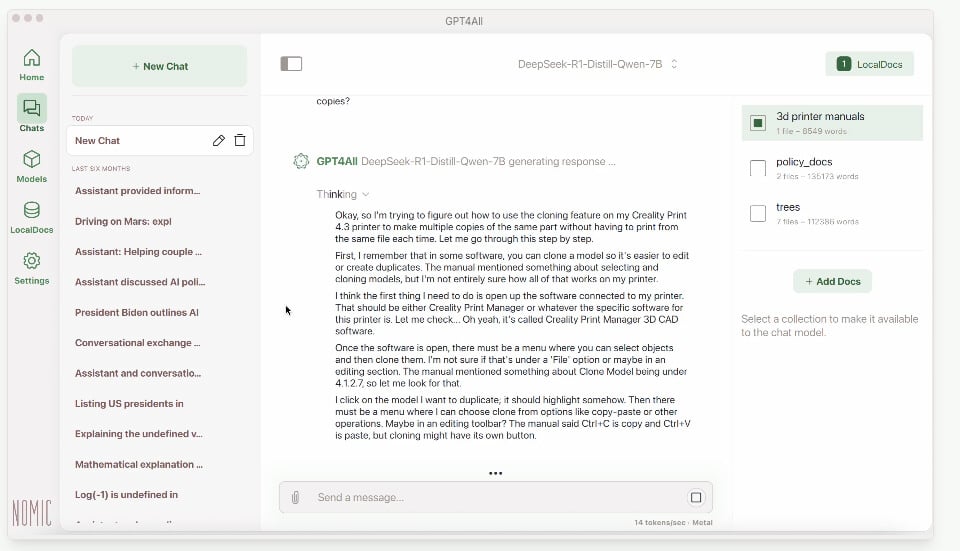
L’installation est tout aussi facile : il suffit de télécharger l’application depuis gpt4all.io, de l’installer, puis de choisir un modèle pour commencer à discuter.

Chat with RTX
Si vous avez carte graphique NVIDIA RTX, vous pouvez aussi essayer Chat With RTX, une solution proposée directement par NVIDIA.
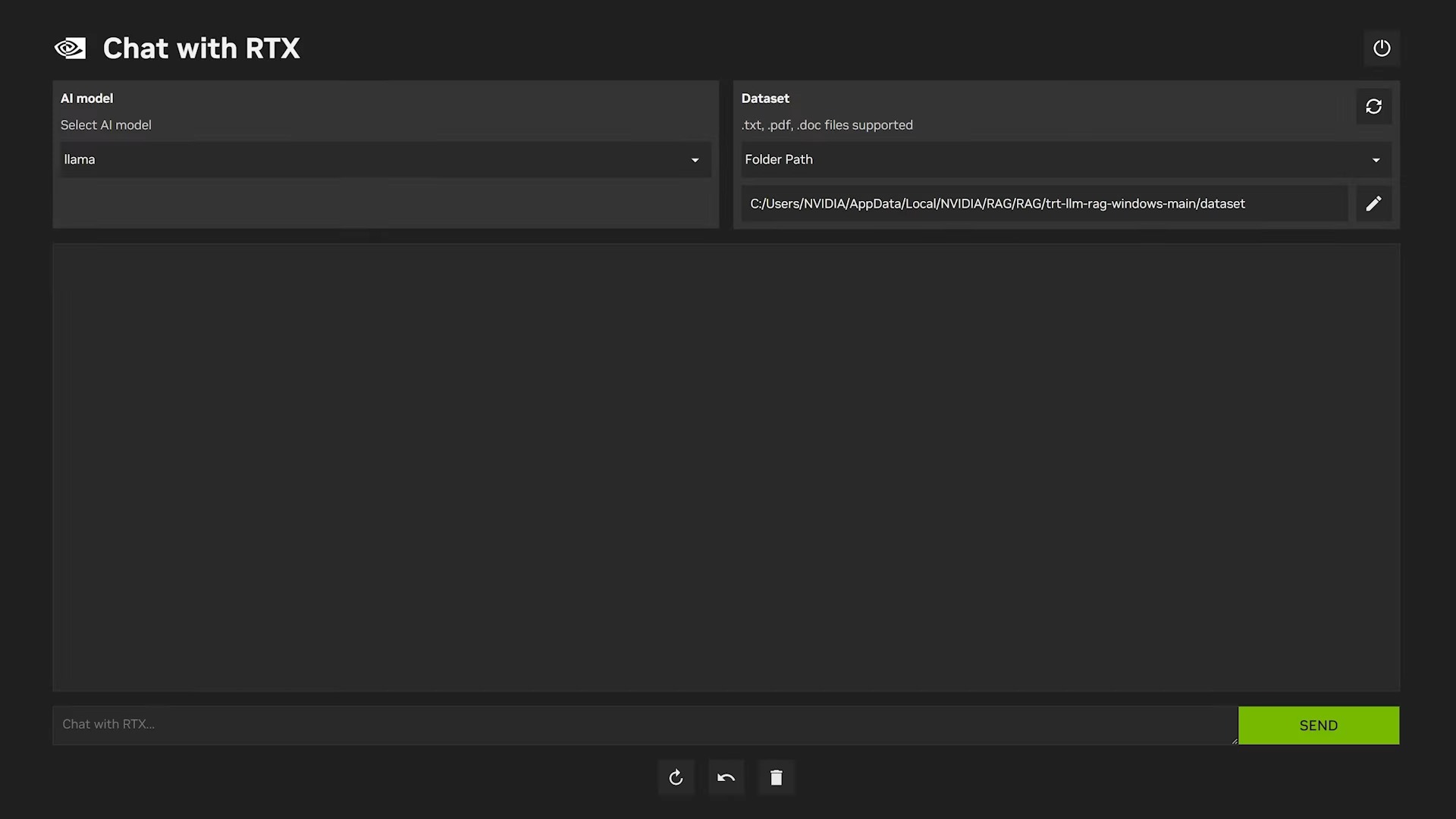
Elle est spécialement optimisée pour tirer parti des GPU RTX et permet d’exécuter des modèles comme Llama 2 ou Mistral 7B avec une fluidité impressionnante. Le téléchargement se fait depuis le site officiel de Nvidia et l’installation est aussi simple que celle d’un jeu vidéo. L’application propose une interface épurée où vous pouvez tester directement le modèle et voir les performances offertes par votre GPU.

Intermédiaire : lignes de commande et polyvlance
Si vous voulez plus de contrôle sur le fonctionnement du modèle, l’exécuter via la ligne de commande est une excellente option.
Ollama
Cela vous permet de gérer les modèles plus finement, d’optimiser leurs performances et même de les appeler depuis d’autres applications. La solution la plus accessible pour utiliser un LLM en ligne de commande, sans trop de complexité, c’est Ollama.

Sur Mac et GNU/Linux, l’installation est particulièrement simple grâce à Homebrew. Une seule commande dans le terminal suffit : winget install Ollama ou curl -fsSL https://ollama.ai/install.sh | sh.
Une fois installé, l’utilisation est tout aussi simple. Pour télécharger et exécuter un modèle, il suffit de taper dans le terminal : ollama run mistral… Le modèle se télécharge automatiquement et se lance en quelques secondes. Vous pouvez maintenant lui poser n’importe quelle question, directement en ligne de commande.
Si vous voulez un contrôle encore plus fin sur les modèles, Llama.cpp est une alternative plus technique, mais ultra performante. Il fonctionne sur toutes les plateformes et permet d’optimiser l’exécution des modèles selon le matériel disponible. L’installation demande quelques étapes supplémentaires.
Llama.cpp est particulièrement utile si vous voulez expérimenter différents niveaux de quantification, c’est-à-dire réduire la taille mémoire du modèle en compressant certains calculs pour améliorer les performances. C’est un excellent outil pour obtenir de meilleures performances sur des machines modestes, tout en gardant un bon niveau de qualité des réponses.
Utiliser un LLM en ligne de commande vous donne aussi accès à des intégrations plus flexibles. Vous pouvez par exemple brancher Ollama ou Llama.cpp à un script Python, ou encore les utiliser en mode serveur pour interagir avec une API locale. C’est une excellente manière d’avoir un assistant IA plus puissant et adaptable que ce que propose une interface graphique standard.
Si vous voulez intégrer un LLM dans un site web, voici comment exposer Ollama comme API locale : ollama serve… Cela ouvre une API compatible avec OpenAI sur http://localhost:11434. Maintenant, vous pouvez interroger votre LLM depuis une page web, en local, sans dépendance externe.
LocalAI
Si vous cherchez une solution plus polyvalente qui ne se limite pas à la génération de texte, LocalAI est un excellent choix. Contrairement aux outils comme LM Studio ou GPT4All, qui se concentrent sur les LLM, LocalAI est conçu comme une alternative open-source aux API d’OpenAI. Il permet non seulement d’exécuter des modèles de langage, mais aussi de gérer des fonctionnalités avancées comme la transcription audio, la génération d’images ou encore l’intégration avec des bases de données vectorielles.
L’installation est assez simple et fonctionne sur Windows, macOS et Linux. Sur une machine Linux ou Mac, on peut l’installer via Docker pour éviter d’avoir à configurer manuellement les dépendances. Une commande suffit pour lancer un serveur LocalAI prêt à l’emploi, tout est bien documenté.
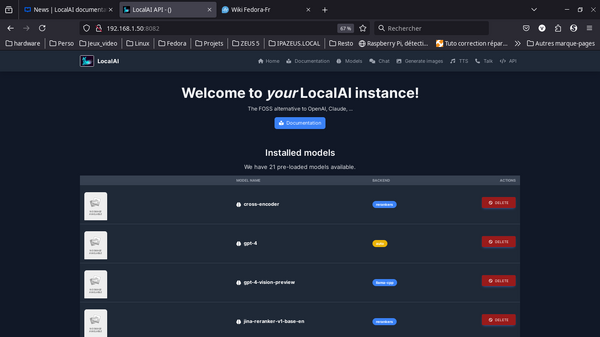
Une fois lancé, LocalAI propose une API 100% compatible avec OpenAI, ce qui signifie que toutes les applications qui utilisent des requêtes OpenAI (comme ChatGPT API) peuvent être redirigées vers votre serveur local. Vous pouvez ensuite ajouter des modèles en les téléchargeant directement depuis Hugging Face ou en utilisant des backends comme llama.cpp pour les modèles de texte, whisper.cpp pour la transcription audio ou encore Stable Diffusion pour la génération d’images.
Si vous êtes à l’aise avec les lignes de commande et que vous cherchez une solution qui va bien au-delà du simple chatbot, LocalAI est un outil puissant qui mérite d’être testé. En combinant modèles de texte, reconnaissance vocale, génération d’images et embeddings, il transforme votre ordinateur en véritable assistant IA local, capable de traiter différents types de données sans jamais envoyer une requête sur Internet.
Avancé : personnalisation et fine-tuning
Si vous voulez aller encore plus loin, il est possible de personnaliser ton modèle et même de l’entraîner sur tes propres données. Pour cela, l’outil de référence est Hugging Face Transformers. Cette bibliothèque open-source permet de télécharger, exécuter, modifier et entraîner des modèles de manière ultra flexible.
L’installation est relativement simple. Sur Windows, macOS et Linux, il suffit d’installer les bibliothèques nécessaires avec pip : pip install torch transformers accelerate.
Ensuite, les choses se corsent, il faut utiliser un script python pour charger le modèle et générer du texte…. L’avantage de cette approche est que vous pouvez modifier les hyperparamètres, affiner les réponses et tester plusieurs modèles très facilement.
Si vous voulez personnaliser un modèle avec vos propres données, vous pouvez utiliser QLoRA, une technique qui permet de fine-tuner un LLM sans nécessiter une énorme puissance de calcul. Cela vous permet par exemple de spécialiser un modèle sur un domaine spécifique (finance, droit, santé). Mais entre nous, si vous arrivez là, c’est que vous n’avez pas besoin de nous.
Exemple avec un Mac mini M4
Si vous partez de zéro, pas de souci. Avec l’arrivée du Mac mini M4, Apple a poussé encore plus loin les performances de ses puces Apple Silicon.
")
Avec son petit prix, cette machine est une plateforme idéale pour exécuter des modèles de langage locaux, faire de la transcription audio en temps réel, et même générer des images et vidéos IA avec des performances impressionnantes.

Un Mac mini M4 avec 16 Go de RAM peut faire tourner des modèles 7B à 13B sans difficulté. Un modèle comme Mistral 7B, optimisé pour Metal et le GPU Apple, offre des réponses instantanées avec une consommation d’énergie minimale. Personnellement, j’utilise DeepSeek R1 Distilled (Qwen 7B).
Vous pouvez facilement utiliser LM Studio ou Ollama pour interagir avec l’IA en local, sans passer par le cloud. Si vous travaillez dans la rédaction, la programmation ou l’analyse de données, le Mac mini devient un assistant personnel ultra-performant, capable de générer du texte, résumer des documents et même analyser des PDF directement depuis un modèle open-source.
Sur un Mac mini M4, Ollama tire parti de ces optimisations et permet de générer du texte à une vitesse de 10 à 15 tokens/seconde sur un modèle 7B, c’est donc même mieux qu’un ChatGPT gratuit.
Avec 24 ou 32 Go de RAM ou plus, le Mac mini M4 peut gérer des modèles plus lourds comme Llama 2 13B en pleine précision, voire des modèles 30B en version optimisée. Cela vous permet d’avoir des réponses plus détaillées et précises, tout en restant dans un environnement 100 % local. Si vous travaillez dans la recherche ou la data science, vous pouvez entraîner des modèles plus petits, les affiner avec QLoRA et les exécuter directement sur votre Mac sans passer par un serveur distant.
Alors, on tente ?
Vous l’aurez compris, exécuter un LLM sur un ordinateur personnel est un projet tout à fait réalisable en 2025, y compris pour un utilisateur non expert, grâce aux progrès des modèles open-source et des outils d’installation simplifiés.
L’IA générative n’est plus réservée aux data centers : chacun peut désormais avoir son « ChatGPT personnel » tournant sur son PC, pour peu qu’il y consacre un peu de temps et de ressources.
Rendez-vous un mercredi sur deux sur Twitch, de 18h à 20h, pour suivre en direct l’émission SURVOLTÉS produite par Frandroid. Voiture électrique, vélo électrique, avis d’expert, jeux ou bien témoignages, il y en a pour tous les goûts !






















Ce contenu est bloqué car vous n'avez pas accepté les cookies et autres traceurs. Ce contenu est fourni par Disqus.
Pour pouvoir le visualiser, vous devez accepter l'usage étant opéré par Disqus avec vos données qui pourront être utilisées pour les finalités suivantes : vous permettre de visualiser et de partager des contenus avec des médias sociaux, favoriser le développement et l'amélioration des produits d'Humanoid et de ses partenaires, vous afficher des publicités personnalisées par rapport à votre profil et activité, vous définir un profil publicitaire personnalisé, mesurer la performance des publicités et du contenu de ce site et mesurer l'audience de ce site (en savoir plus)
En cliquant sur « J’accepte tout », vous consentez aux finalités susmentionnées pour l’ensemble des cookies et autres traceurs déposés par Humanoid et ses partenaires.
Vous gardez la possibilité de retirer votre consentement à tout moment. Pour plus d’informations, nous vous invitons à prendre connaissance de notre Politique cookies.
Gérer mes choix