
L’intelligence artificielle continue de repousser les limites de ce qui est possible. Parmi les derniers développements, OpenAI o1 est tout nouveau.
Pour aller plus loin
Oubliez ChatGPT GPT-4, voici OpenAI o1 : l’IA qui peut « réfléchir »
OpenAI déclare que cette AI peut raisonner, grâce à son utilisation de l’apprentissage par renforcement. Mais en quoi cette méthode est-elle si révolutionnaire et comment se compare-t-elle à d’autres modèles comme GPT-4o, Google Gemini ou Claude AI ?
L’apprentissage par renforcement : une nouvelle approche
Contrairement à GPT-4o et aux modèles précédents, Open AI o1 n’imite pas ses schémas d’entraînement, mais utilise plutôt l’apprentissage par renforcement pour résoudre par lui-même les problèmes qui lui sont présentés.
Mais qu’est-ce que l’apprentissage par renforcement ? En gros, c’est une méthode où l’IA apprend par essais et erreurs. Elle reçoit des récompenses pour les bonnes actions et des pénalités pour les mauvaises, ce qui lui permet de s’améliorer au fil du temps.
OpenAI a commenté que la formation d’Open AI o1 a été réalisée avec un ensemble de données sur mesure et un nouvel algorithme d’optimisation. Cela signifie que l’IA a été entraînée sur des données spécifiques et avec des méthodes avancées pour maximiser ses performances. Contrairement aux modèles classiques qui s’appuient sur les patterns appris lors de leur entraînement pour générer des réponses, Open AI o1 utilise l’apprentissage par renforcement pour résoudre les problèmes de manière autonome.
Mettre fin aux hallucinations ?
L’un des principaux avantages d’Open AI o1 est sa capacité à réduire les « hallucinations » de l’IA. Cela ne veut pas dire que l’IA ne fera pas d’erreurs ou n’inventera pas de réponse. Mais OpenAI affirme que c’est moins fréquent que dans les versions précédentes de GPT. Pour rappel, les hallucinations sont des réponses incorrectes ou inventées que l’IA génère parfois, souvent en raison de données d’entraînement insuffisantes ou biaisées.
Les modèles classiques, comme GPT-4o, sont entraînés sur de vastes quantités de données textuelles pour apprendre les structures et les motifs du langage. Ils utilisent généralement une architecture de réseau neuronal appelée « transformer« , qui permet de traiter efficacement de longues séquences de texte.
Ces modèles de langage (LLM, on vous explique ce que c’est ici) sont comme des étudiants qui ont ingurgité des tonnes de bouquins et qui essaient de répondre aux questions en se basant sur ce qu’ils ont appris.
Lors de l’utilisation, ces modèles prédisent le token (mot ou partie de mot) suivant le plus probable en fonction du contexte fourni. Après le pré-entraînement, ils peuvent être affinés sur des tâches spécifiques pour améliorer leurs performances dans certains domaines.
Open AI o1 utilise ensuite une « chaîne de pensée » pour traiter les requêtes, de la même manière que les humains traitent les problèmes en les parcourant étape par étape.
La principale chose qui distingue ce nouveau modèle du GPT-4o est sa capacité à résoudre des problèmes complexes, tels que le développement et les mathématiques, bien mieux que ses prédécesseurs tout en expliquant son raisonnement, selon OpenAI.
OpenAI a fait participer son nouveau LLM à un concours qui s’appelle Codeforces. Des programmeurs du monde entier y participent pour résoudre des problèmes complexes. Et devinez quoi ? Il s’est mieux débrouillé que 89 % des participants humains. Pour OpenAI, ce n’est que le début : ils expliquent que la prochaine version sera capable de résoudre des problèmes compliqués en physique, chimie et biologie, du nouveau des étudiants en doctorat.
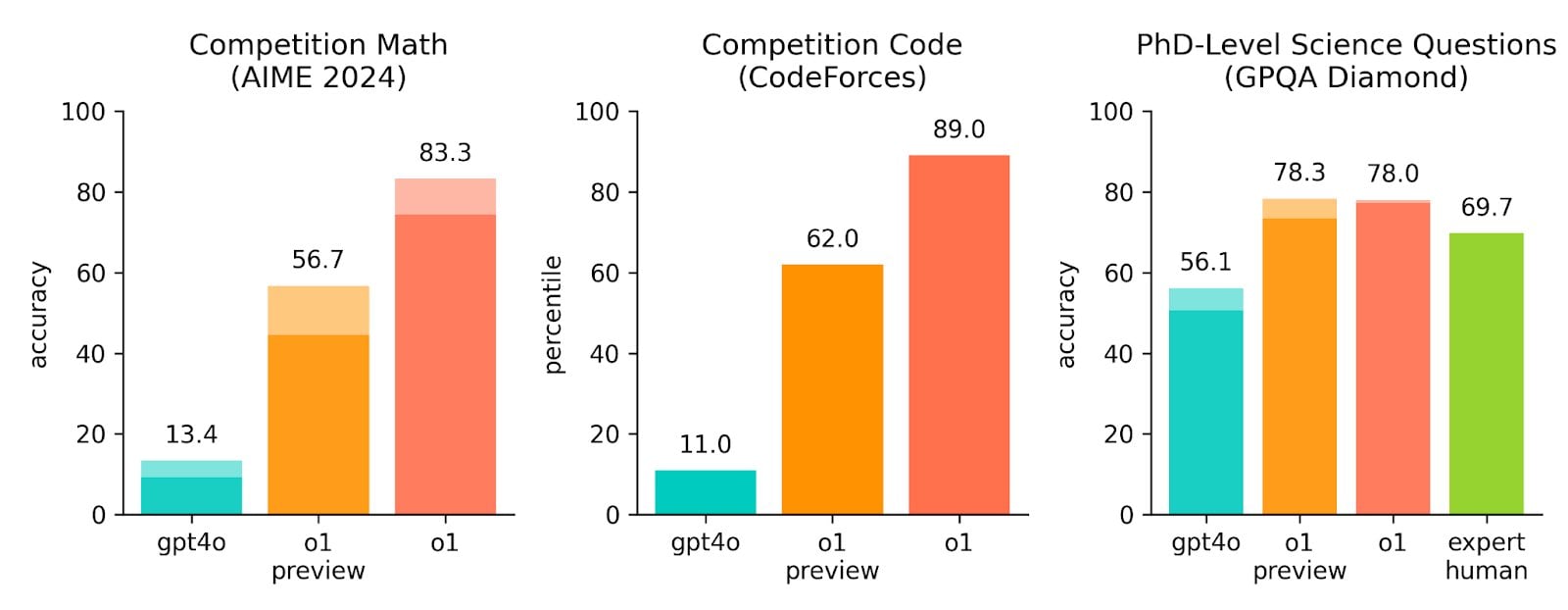
En même temps, o1 n’est pas aussi performant que GPT-4o dans de nombreux domaines. Il n’est pas aussi performant en matière de connaissances factuelles sur le monde. Il n’a pas non plus la capacité de naviguer sur le Web ou de traiter des fichiers et des images.
Évidemment, on ne connaît pas toujours les détails exacts du fonctionnement de chaque modèle peuvent varier. Pourquoi ? Car les entreprises qui les développent ne divulguent pas toujours toutes les informations sur leurs méthodes d’entraînement ou leur architecture précise. Cela peut rendre difficile une comparaison directe entre les modèles. Cependant, l’apprentissage par renforcement semble être une avancée notable.
Prenons un exemple : un calcul
Ce n’est pas simple de démontrer les capacités d’un LLM ainsi, mais tentons avec cette requête :
Pouvez-vous calculer à quel prix de l’essence une voiture électrique moyenne (consommation mixte à 17 kWh) devient moins rentable qu’une voiture thermique hybride légère, sachant que le coût de l’électricité est de 0,25 euros par kWh ? Pour ce calcul, vous pouvez supposer que la voiture thermique hybride légère consomme en moyenne 5 litres d’essence pour 100 kilomètres. Merci de fournir une explication détaillée de votre calcul
Avec o1-preview, on peut voir les différentes étapes de décomposition de ma requête très simple, cela a pris 8 secondes selon OpenAI :
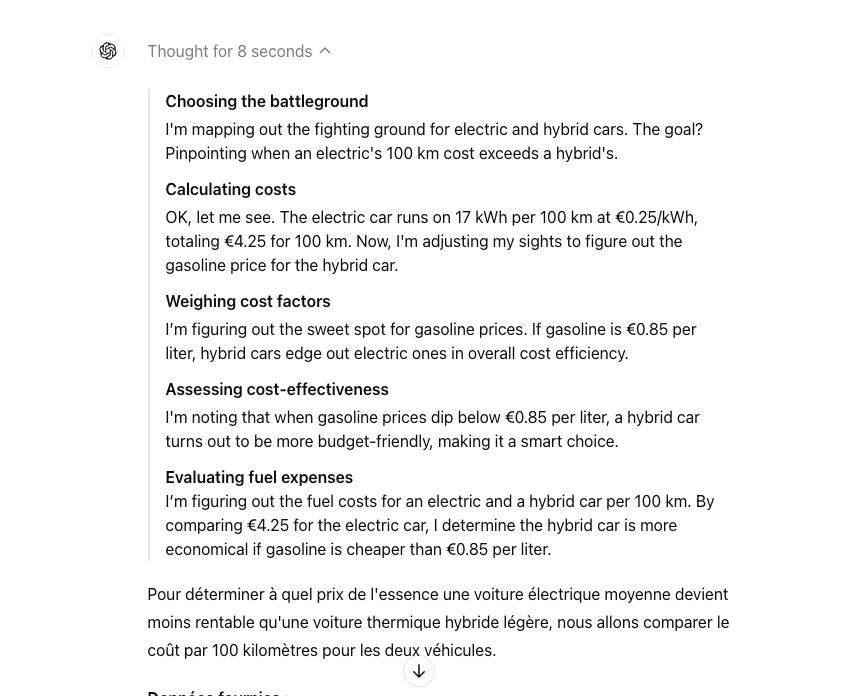
Comme vous pouvez le voir, les phrases créent une illusion de réflexion étape par étape.
OpenAI ne croit pas à l’idée d’assimiler la pensée des modèles d’IA à la pensée humaine. Mais l’interface est censée montrer comment le modèle passe plus de temps à traiter et à approfondir la résolution des problèmes.
Si vous êtes curieux de la réponse finale, la voici :

Évidemment, j’ai obtenu la même réponse avec GPT-4o. Les anglophones aiment tester un des prompts très connus : « How many R’s are there in Strawberry?« . Les « anciens modèles » ont tendance à prétendre à tort que le mot « Strawberry » n’a que deux R parce qu’il ne décompose pas correctement le mot.
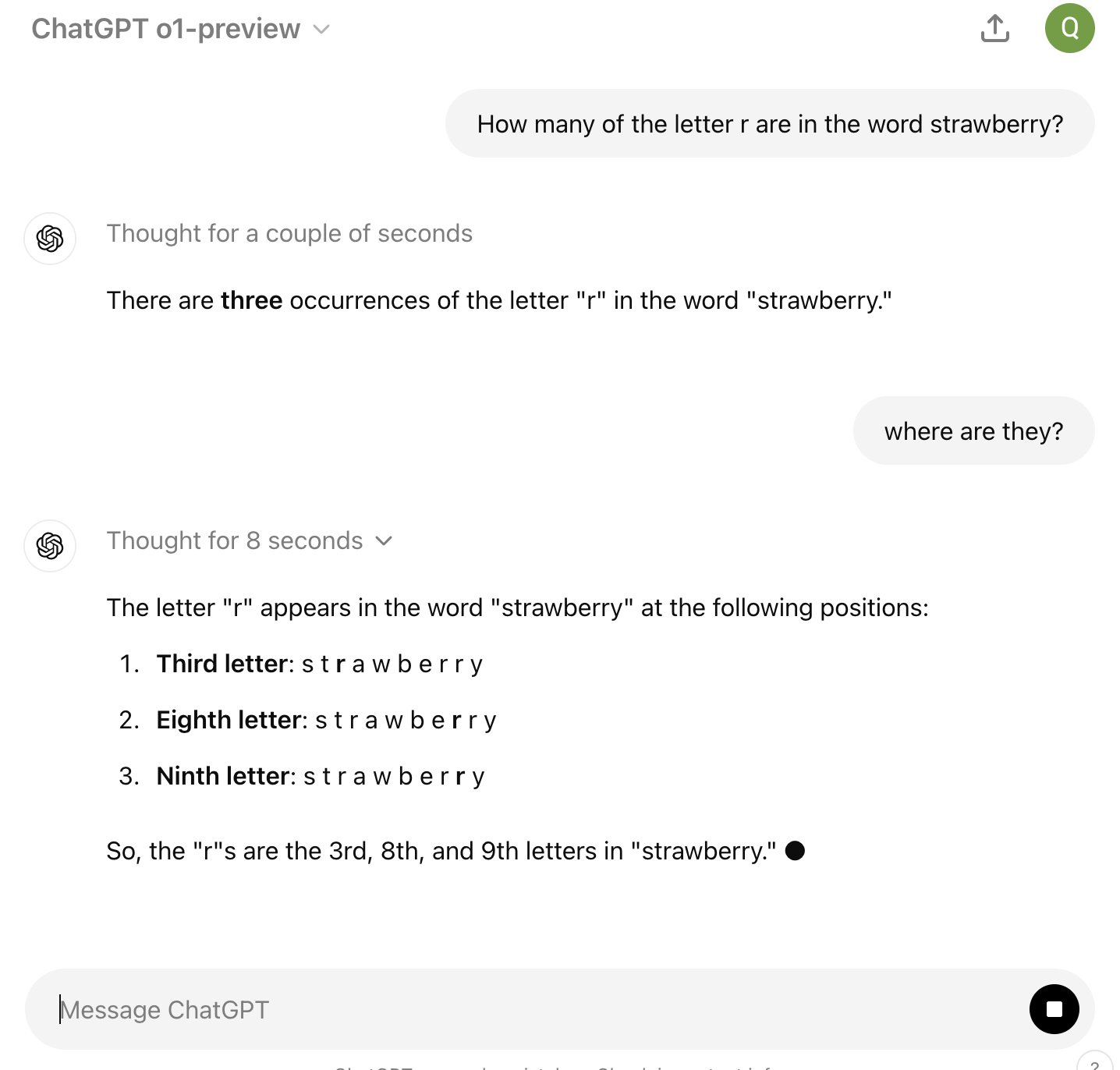
Alors, Open AI o1 est-il vraiment la révolution qu’on nous promet ? Honnêtement, c’est encore trop tôt pour le dire. On a vu tellement de « révolutions » dans l’IA ces dernières années qu’on a appris à être prudents.
Ce qui est sûr, c’est que l’apprentissage par renforcement est une piste prometteuse. Si GPT-o1 tient ses promesses, on pourrait avoir des IA plus fiables, plus créatives, et moins susceptibles de délirer.
Comment coûte OpenAI GPT-o1 et comment y accéder ?
Les utilisateurs de ChatGPT Plus et Team ont accès à o1-preview et o1-mini à partir d’aujourd’hui, tandis que les utilisateurs Enterprise et Edu y auront accès au début de la semaine prochaine.
OpenAI a annoncé qu’il prévoyait d’offrir l’accès à o1-mini à tous les utilisateurs gratuits de ChatGPT, mais n’a pas encore fixé de date de sortie.
L’accès des développeurs à o1 est très coûteux : dans l’API, o1-preview coûte 15 dollars par million de jetons d’entrée, ou morceaux de texte analysés par le modèle, et 60 dollars par million de jetons de sortie. À titre de comparaison, GPT-4o coûte 5 dollars par million de jetons d’entrée et 15 dollars par million de jetons de sortie.

Votre café et votre dose de tech vous attendent sur WhatsApp chaque matin avec Frandroid.



















Ce contenu est bloqué car vous n'avez pas accepté les cookies et autres traceurs. Ce contenu est fourni par Disqus.
Pour pouvoir le visualiser, vous devez accepter l'usage étant opéré par Disqus avec vos données qui pourront être utilisées pour les finalités suivantes : vous permettre de visualiser et de partager des contenus avec des médias sociaux, favoriser le développement et l'amélioration des produits d'Humanoid et de ses partenaires, vous afficher des publicités personnalisées par rapport à votre profil et activité, vous définir un profil publicitaire personnalisé, mesurer la performance des publicités et du contenu de ce site et mesurer l'audience de ce site (en savoir plus)
En cliquant sur « J’accepte tout », vous consentez aux finalités susmentionnées pour l’ensemble des cookies et autres traceurs déposés par Humanoid et ses partenaires.
Vous gardez la possibilité de retirer votre consentement à tout moment. Pour plus d’informations, nous vous invitons à prendre connaissance de notre Politique cookies.
Gérer mes choix