
Pour les néophytes, la fiche technique d’un appareil photo ou d’une caméra a de quoi créer des sueurs froides. Si, pendant longtemps, on s’est contenté d’indiquer la définition ainsi que le nombre d’images par seconde, on voit apparaître de plus en plus de termes qui peuvent paraître complexes. Des termes comme 4:2:2 10 bits, 60p, 30i, H.265 ou Long GOP peuvent rapidement perdre l’utilisateur. Quel est l’avantage réel apporté par le 10 bits par rapport au 8 bits ? Par le 4:2:2 par rapport au 4:2:0 ? Ou par le H.265 par rapport au H.264.
Dans ce dossier, on va tout vous expliquer pour que la définition, le balayage, la quantification, la décimation ou la compression vidéo n’aient plus de secrets pour vous.
La définition en vidéo, de la SD à l’UHD-2
L’œil humain a une capacité de discrimination entre deux détails et un angle de vision limités. Afin de proposer aux utilisateurs une impression toujours plus grande d’immersion dans l’image, les constructeurs ont souhaité à la fois augmenter la taille des écrans et réduire la distance entre l’écran et le spectateur (à taille égale ce qui est plus près semble plus grand et occupe une part plus importante de l’espace visuel).
Pour aller plus loin
Quels sont les meilleurs TV (QLED ou Oled) de 2025 ?
Pour y parvenir tout en gardant une qualité d’image agréable à l’œil, il a donc fallu augmenter la définition des images — à ne pas confondre avec la résolution. On est donc passé, en sautant quelques étapes intermédiaires — aujourd’hui d’usage marginal — de la définition standard (SD, 720 points x 576 lignes utiles en France) à la haute définition (Full HD, 1920×1080 pixels) puis à l’ultra haute définition (UHD, 3840×2160 pixels). L’UHD-2 (7680 x 4320 pixels) a également déjà été mise au point puisqu’une partie des programmes sont ainsi diffusés au Japon ou via Internet, souvent pour des évènements spécifiques (sportifs en général), mais cela reste anecdotique à l’échelle mondiale, y compris sous nos latitudes. Notons également que, depuis le passage à la haute définition, le rapport largeur/hauteur de l’image s’est transformé, passant de 4/3 à 16/9.

Pour la précision, les vrais formats « K » (2K, 4K, 8K…) sont des définitions multiples de 1024 dans leur largeur. Ainsi, le terme 4K signifie que la dimension horizontale des images est de 4096 pixels. Ils sont généralement réservés au cinéma. C’est la raison pour laquelle on va parfois retrouver les termes de DCI 4K, pour Digital Cinema Initiatives, en opposition à l’UHD 4K.
Pour le grand public, les normes réellement disponibles sont celles citées au-dessus (HD, UHD, UHD-2). Sauf exception rarissimes, ce sont les seuls présentes sur les appareils de captation (caméras, appareils photo, smartphone…) que nous rencontrons, y compris pour de nombreux vidéastes professionnels.
Cela ne change pas grand-chose en pratique, car toute la chaine captation/traitement/diffusion reste cohérente. Quand un fabricant vend par exemple un téléviseur, un smartphone ou un appareil photo filmant en 4K, il s’agit donc souvent un argument commercial abusif, car le format réel est presque toujours l’UHD. Si la « vraie » 4K est proposée, elle le sera sous le terme de DCI 4K.
Le balayage, en mode progressif « p » ou entrelacé « i »
Le cinéma, historiquement à l’origine de nombreux fondamentaux techniques, procède par succession d’images entières (sur pellicule) à la fréquence de 24 images par seconde, c’est ce qu’on appelle le balayage progressif (donc ici 24p).
Une image vidéo, comme à la télévision, est par contre composée de points répartis sur des lignes horizontales successives. Dans le passé, les possibilités de transmission des informations étaient plus réduites qu’aujourd’hui. Il n’était pas possible d’acheminer des images entières à la fréquence suffisante pour garantir à l’œil une impression de fluidité des mouvements.

En raison de certaines caractéristiques de la vision humaine, comme la persistance rétinienne, et de considérations physiques et mathématiques il a été décidé d’acheminer 50 fois par seconde des demi-images, c’est-à-dire des trames composées d’une ligne sur deux, d’où le terme entrelacé ou interlace. C’est ce qu’on appelle aujourd’hui le défilement 50i. Dans le système américain, on était proche d’un défilement à 60 trames par seconde, d’où le 60i. Toutes les cadences existantes actuellement sont dérivées de ces standards et proposent des cadences supérieures afin de permettre un meilleur rendu des mouvements — comme le 50p utilisé aux États-Unis pour certaines chaines sportives — ou de réaliser des ralentis.
Le pixel, composé de trois sous pixels
Le pixel, ou « picture element », est l’unité de base d’une image numérique. Ce point coloré est composé de trois sous-pixels reproduisant chacun une valeur dans l’une des trois couleurs primaires de la vidéo : rouge, vert et bleu. C’est le fameux « RVB » (« RGB » en anglais).
Une image numérique est composée de plusieurs pixels, jusqu’à plusieurs millions en HD (plus de 2 millions) ou UHD (plus de 4 millions).
8 bits, 10 bits et plus : la quantification
Première précision d’importance : il faut absolument dissocier les termes « bit » et « bytes ». « Byte » est en effet la traduction anglaise du terme « octet » et signifie donc un ensemble de 8 « bits » (qui garde la même appellation dans les deux langues).
Le bit est l’unité de base du calcul numérique. Le nombre de bits détermine la finesse d’enregistrement d’une information, ce qu’on appelle son échantillonnage. Chaque bit peut avoir deux valeurs : 0 ou 1. Si on affecte par exemple à chaque valeur une nuance de gris, 0 ou 1 pourraient être par exemple : 0 = noir et 1 = blanc.
Si la même information est maintenant codée sur 2 bits, nous avons les 4 résultats suivants possibles :
- Bit 1 : 0 ou 1
- Bit 2 : 0 ou 1
Nous avons donc pour cette information 4 résultats possibles (donc noir, blanc et 2 densités de gris possibles selon notre exemple) :
| bit n°1 | bit n°2 |
|---|---|
| 0 | 0 |
| 1 | 1 |
Les différentes possibilités d’un codage d’une information sur deux bits sont donc : 0 0 / 0 1 / 1 0 / 1 1. D’un point de vue mathématique, pour connaître le nombre possible de variétés de codage d’une information sur 2 bits on a donc : 2 x 2 = 4 (ou 2²) possibilités.
Si la même information est codée par 3 bits, nous avons 8 possibilités :
| bit n°1 | bit n°2 | bit n°3 |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 1 | 1 |
Les valeurs possibles sont donc : 0 0 0 / 0 0 1 / 0 1 0 / 0 1 1 / 1 0 0 / 1 0 1 / 1 1 0 / 1 1 1. D’un point de vue mathématique, pour connaître le nombre possible de valeurs d’une information sur 3 bits on a donc : 2 x 2 x 2 = 8 (ou 2³) possibilités (ou noir, blanc et 6 densités de gris toujours selon notre exemple).
Comme on le voit, chaque bit pouvant avoir 2 valeurs, à chaque fois qu’on code sur un bit supplémentaire, on double le nombre de valeurs possibles pour chaque information. Pour connaître le nombre de résultats possibles pour une information il suffit donc de calculer le nombre de valeurs possible pour un bit (2) puissance nombre de bits. Exemple : pour un échantillonnage sur 8 bits d’un type d’information, nous avons donc 2⁸ valeurs possibles soit 256.
En photo ou vidéo numérique, nous avons vu que chaque pixel est composé de trois éléments de couleur, chacun codé numériquement (RVB). Une image codée ou échantillonnée sur 8 bits a donc :
256 (rouge) x 256 (vert) x 256 (bleu) = 16 777 216 possibilités, ce sont les fameuses 16 millions de couleurs de l’imagerie 8 bits.
L’ajout d’un bit de codage supplémentaire permet donc de doubler le nombre de valeurs possibles pour chaque couleur. La différence, qui peut sembler minime en vidéo entre 8 et 10 bits, est donc en réalité considérable, car on passe de 16 millions à plus d’un milliard de valeurs colorimétriques différentes (2¹⁰ = 1024, donc 1024 x 1024 x 1024 en RVB).
On dépasse ici largement le nombre de couleurs discernables théoriquement par l’œil humain, c’est donc surtout pour garder de la marge en postproduction, où l’on peut être amené à modifier — et donc souvent à dégrader — les paramètres enregistrés pour donner un aspect particulier avec l’étalonnage. Et cela sans pouvoir ajouter de nouvelles informations, d’où la dégradation. Il est donc utile, afin de garder un aspect agréable au regard, qu’il y ait un surplus d’information afin de disposer d’une marge d’action. On évite ainsi divers effets désagréables, par exemple les effets de rupture dans les dégradés.
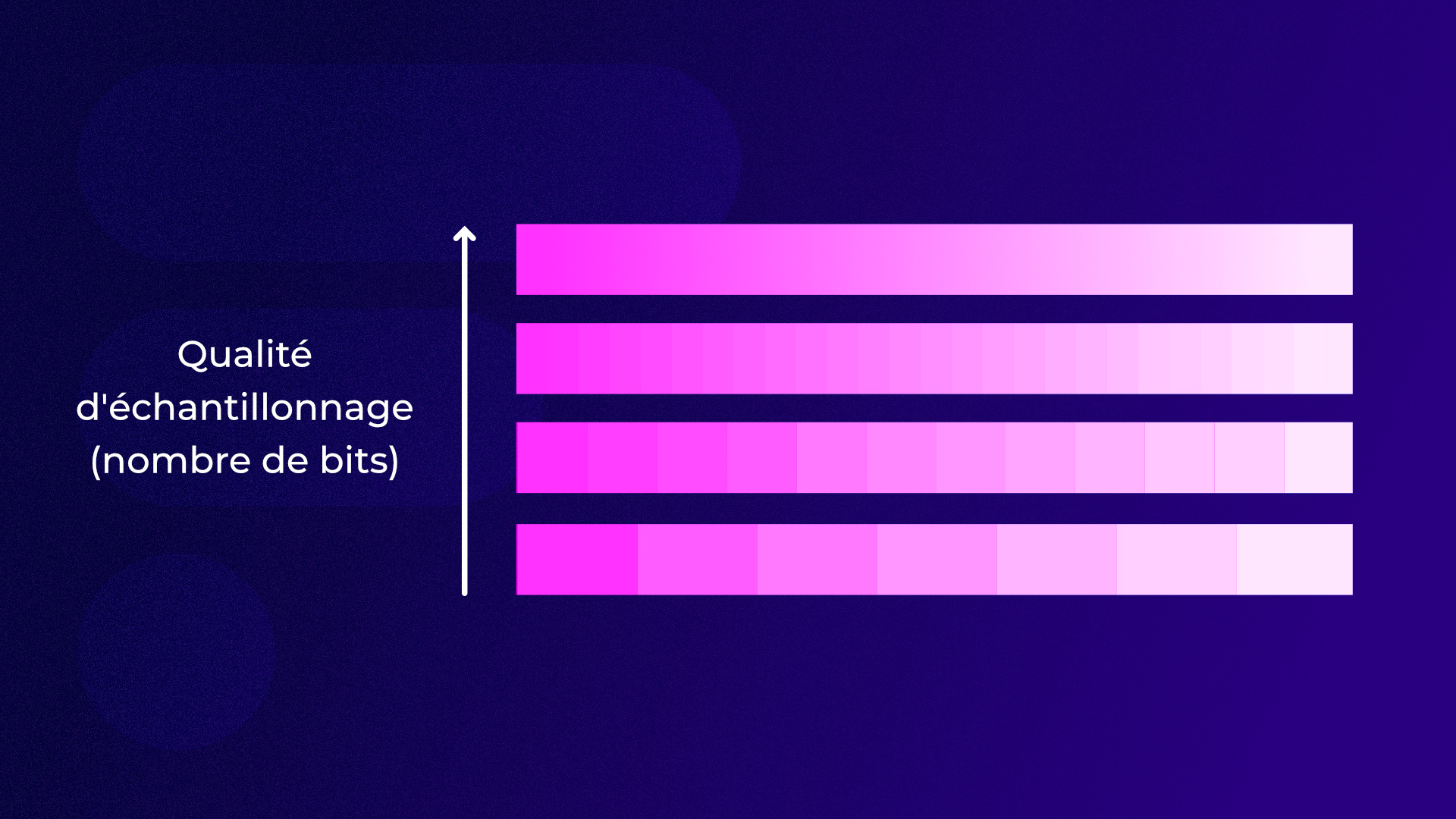
C’est évidemment également très utile dans le cadre d’une augmentation de la définition, car, selon ses caractéristiques, un même dégradé de couleur peut réclamer une plus grande finesse d’échantillonnage (donc plus de valeurs colorimétriques intermédiaires) pour être retransmis sur une dalle plus grande, mieux définie et conçue pour être observée de plus près tout en évitant ce type de désagrément. Cela permet enfin des applications dans le domaine de la HDR (« high dynamic range » ou grande plage dynamique en français) : la très grande palette colorimétrique permet de reproduire des informations dans des zones de l’image présentant entre elles des écarts de luminosité très importants.
4:4:4, 4:2:2, 4:2:0… : la décimation
Le poids d’un fichier dépend du nombre d’informations qu’il contient. Hors compression, dans le cas d’un fichier vidéo, il varie donc selon :
- la définition : le nombre de pixels qui composent l’image
- le nombre de bits : la finesse d’échantillonnage de chaque pixel
- la cadence, le balayage et la durée : le nombre d’images qu’il contient
Afin de limiter le bridage qualitatif lié aux capacités de stockage et de transmission disponibles, les ingénieurs ont imaginé des solutions de diminution du flux d’information en tentant de trouver le meilleur compromis qualité/poids en fonction de l’environnement technique du moment et de la vision humaine.
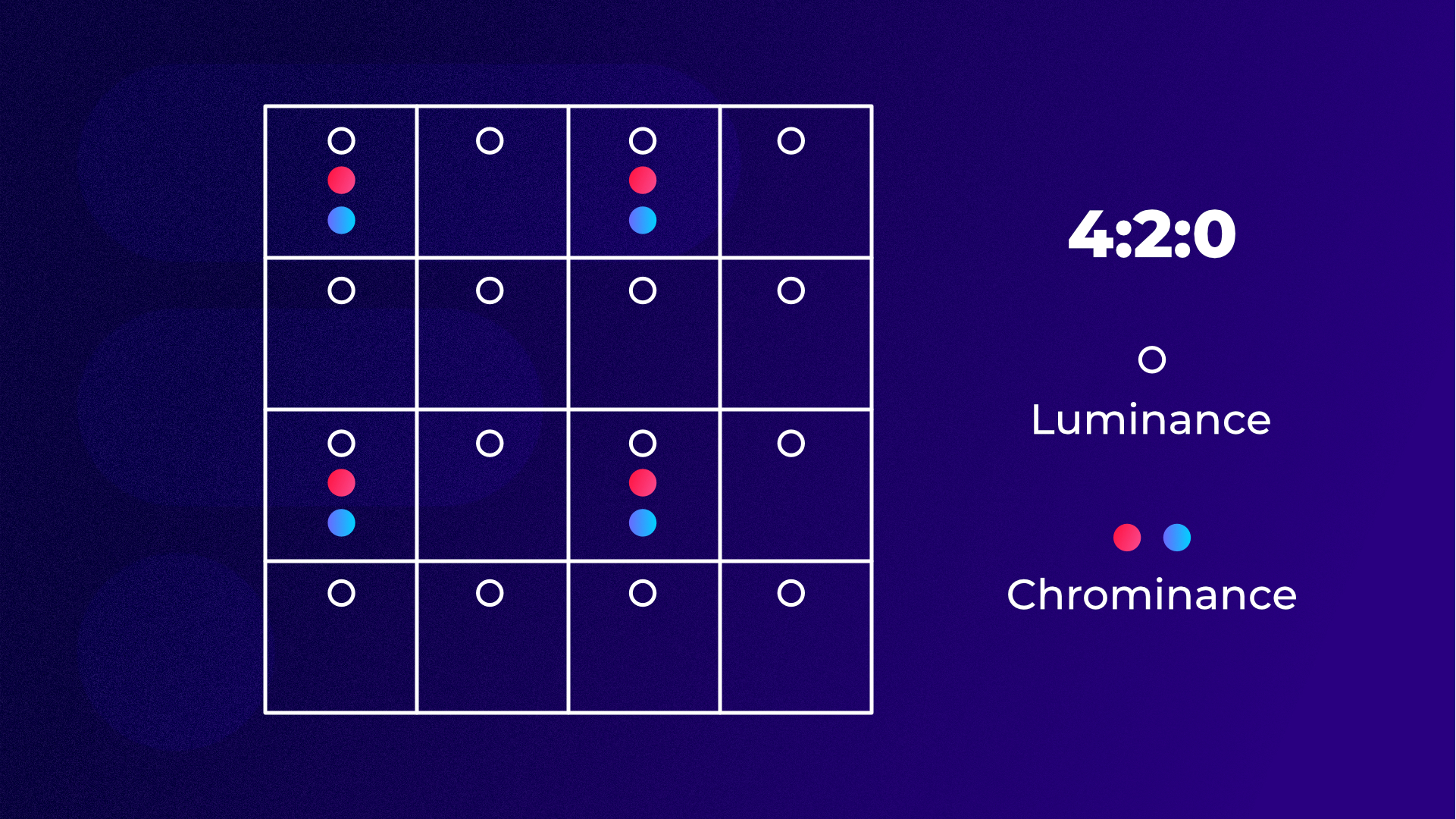
Afin de proposer des images à la définition jugée suffisante, ils ont ainsi décidé dans un premier temps de convertir par calcul mathématique le signal RVB (rouge vert bleu), qui décrivait l’image en nuances colorimétriques, en un signal séparé en trois composantes. C’est l’étape dite du « matriçage » :
- La « luminance » (Y) contient les informations liées à l’intensité lumineuse pour chaque pixel (c’est un signal noir et blanc codé en niveaux de gris)
- Les deux autres, dites de « chrominance » contiennent les informations couleurs (Cr et Cb).
Notre œil est plus sensible aux variations d’intensité lumineuse qu’aux nuances de couleur. Afin de réduire les débits d’information pour la diffusion et le stockage, il a donc été décidé de se séparer d’une partie des informations de couleur, uniquement afin de maintenir un niveau de qualité le plus élevé possible pour la vision humaine.
Le principe général est simple : le signal a été découpé par bloc de 4 pixels, et 4:4:4 correspond à un signal non compressé (chacun des trois chiffres correspondant à une composante selon cet ordre Y:Cr:Cb) dans lequel on conserve l’ensemble des informations. Le 4:4:4 est réservé au très haut de gamme professionnel, presque exclusivement utilisé pour le cinéma.

Afin de permettre la transmission d’un flux en direct ou le stockage et la postproduction à partir de fichiers de taille maniable, on ne conserve pas l’intégralité des informations. Le fameux 4:2:2 conserve ainsi l’intégralité des informations de luminance (niveaux de gris) pour chaque pixel de l’image et seulement les informations de couleur d’un pixel sur deux. C’est une option disponible sur les appareils photo haut de gamme, comme le Nikon Z9 ou le Sony Alpha 7S III, et de très nombreuses caméras professionnelles.

Afin d’alléger encore le flux d’information, le 4:2:0 a également été mis au point. Dans ce cas ont fait du 4:2:2 pour une ligne sur deux et on ne garde aucune information couleur dans ligne suivante. C’est le format actuellement le plus répandu sur les appareils de captation grand public, y compris sur smartphones.
Pour aller plus loin
Quels sont les meilleurs smartphones pour la photo en 2025 ?
Sur l’écran final, il faut une information RVB par pixel. L’ensemble du processus est donc inversé en fin de chaine pour la diffusion et les informations manquantes sont reconstituées par interpolation (calcul mathématique d’après les informations des pixels voisins). Naturellement, cette reconstitution finale sera d’autant plus fine que la perte d’information couleur sera réduite.
La compression (MPEG, H.264, H.265…)
Afin de réduire encore la masse d’informations à transmettre ou à stocker, des systèmes de compression permettant d’obtenir des niveaux de réduction du nombre d’informations bien plus importants. Là encore, le processus a lieu en plusieurs étapes.
La compression intra-image
Tout d’abord, on compresse les informations au sein de chaque image, c’est la compression intra-image, également appelée « All-intra » chez certains constructeurs. Le principe général est le même que celui du Jpeg en photo : l’image est découpée en de multiples blocs de pixels.
Au sein de chaque bloc, on décide que, si les informations de pixels voisins sont très proches, on ne garde que celles de l’un d’entre eux. De même, les détails les plus fins, donc les moins rapidement visibles par l’œil, sont codés avec moins de précision.
Correctement dosé, cela permet de conserver un niveau de détails suffisant sur les zones principales de l’image et de conserver une impression générale de bonne qualité, tout en réduisant de manière substantielle la quantité d’information à transmettre. Mal dosé cela entraine l’apparition d’artefacts gênants dont les plus connus sont de gros blocs dans certaines zones de l’image aux valeurs proches. Ce peut-être le cas sur des dégradés dans le ciel ou sur certaines zones s’apparentant à des aplats aux variations minimes.
La compression inter-image
À partir de la norme MPEG, une seconde séquence de compression, dite inter-image (ou IPB), peut lui succéder. Le principe est simple : on regroupe les images par séquences appelées « GOP » de taille variable (pour Group of Picture). À partir de la première image, on ne s’intéresse pour les suivantes qu’aux modifications. En pratique, ça permet une diminution massive de la quantité d’informations à transmettre. Les images sont ensuite reconstituées lors de la décompression (pour la postproduction ou la diffusion).
Pour comprendre le principe, il faut avoir en tête que les images sont stockées dans une mémoire (buffer) en attente de compression, et que celle-ci ne peut avoir lieu que lorsqu’au moins un GOP au complet est stocké. Lors d’une diffusion en direct, cela impose donc un léger différé.

Pour ceux qui veulent aller un peu plus loin, un GOP regroupe 3 types d’images I, P ou B. La première image du GOP (« I ») sert de référence et l’ensemble de ses informations restantes après la compression intra-image sont codées.
Certaines images sont dites « prédites » (P) : quand un objet s’est déplacé sans modification, on ne transmet que le vecteur de mouvement. Quand sa forme a été modifiée, c’est le différentiel entre l’image originale et l’image réelle qui est codé.
Entre ces images I et P ou deux images P, on trouve des images bidirectionnelles (« B ») qui sont codées en fonction des images I ou P entre lesquelles elles sont intercalées. Ce sont les plus légères, car les prédictions sont faites à partir d’images antérieures et postérieures, donc plus précises, les résiduels transmis n’en sont que plus légers.
Le H.264 (ou MPEG-4 AVC)
À partir de ces principes généraux, diverses évolutions ont permis d’affiner les résultats. Ainsi, avec l’apparition du H.264 (une évolution de la norme MPEG-4) dédié à la HD, la compression intra-image a été améliorée. Une meilleure compression rendue possible grâce à la l’usage de blocs de taille en fonction des situations, à un système de prédiction spatial et à l’usage d’un système de compression sans perte réversible. Cela permet à la fois une compression plus performante et un meilleur maintien des détails là où c’est nécessaire.
Une souplesse dans la constitution des GOP et une augmentation de la puissance de calcul liée aux évolutions techniques ont également permis une amélioration de la prédiction pour la compression inter-image. La quantité d’information à transmettre est donc plus légère à taille d’image égale. Le H.264 a notamment permis la diffusion HD via la TNT avec des débits soutenables.
Le H.265 (ou HEVC)
Le H.265, que l’on commence à trouver sur les APN récents les plus pointus en vidéo — comme le Panasonic Lumix S5, le Panasonic Lumix GH6, ou le Fujifilm X-H2S — a lui été pensé pour l’UHD et l’UHD-2 et leur diffusion via des supports autres que télévisuels (smartphone, VOD via internet, etc.).
Il permet à son tour une diminution du poids des informations à transmettre significative à dimension d’image égale. Avec l’augmentation importante de la définition (une image UHD regroupe 4 fois plus de pixels qu’une image Full HD), la probabilité de redondance entre deux zones voisines augmente. L’une des évolutions principales qu’il apporte réside donc dans la possibilité de variation beaucoup plus importante de la taille de blocs donc pour la compression intra-image.
Signalons que chacune de ces évolutions est beaucoup plus gourmande en ressource matérielle que la génération précédente, surtout à l’encodage, et que l’évolution des processeurs est un facteur primordial de leur mise en œuvre. Ainsi, le H.265 est environ 10 fois plus gourmand en ressources de calcul à l’encodage que le H.264 et il est optimisé pour le travail en multicœur.
Retrouvez un résumé du meilleur de l’actu tech tous les matins sur WhatsApp, c’est notre nouveau canal de discussion Frandroid que vous pouvez rejoindre dès maintenant !





















Philippe Bellaïche, sors de ce corps !
Bel article de vulgarisation thanks !
Un bel article, on aurait presque oublié ce que c'était. Merci ;)
Excellent article, merci ça fait plaisir !
"Ou par le H.265 par rapport au H.265. " > aucun ;) *H.264
Ce contenu est bloqué car vous n'avez pas accepté les cookies et autres traceurs. Ce contenu est fourni par Disqus.
Pour pouvoir le visualiser, vous devez accepter l'usage étant opéré par Disqus avec vos données qui pourront être utilisées pour les finalités suivantes : vous permettre de visualiser et de partager des contenus avec des médias sociaux, favoriser le développement et l'amélioration des produits d'Humanoid et de ses partenaires, vous afficher des publicités personnalisées par rapport à votre profil et activité, vous définir un profil publicitaire personnalisé, mesurer la performance des publicités et du contenu de ce site et mesurer l'audience de ce site (en savoir plus)
En cliquant sur « J’accepte tout », vous consentez aux finalités susmentionnées pour l’ensemble des cookies et autres traceurs déposés par Humanoid et ses partenaires.
Vous gardez la possibilité de retirer votre consentement à tout moment. Pour plus d’informations, nous vous invitons à prendre connaissance de notre Politique cookies.
Gérer mes choix